ProyectoTransversal-Grup1
2. Implantación de los servicios
Preparación máquinas
| Name VPC | IP VPC | Subnet | Gateway | Routes | ID Cuenta | ID VPC | Server | | ———– | ———– | ———– | ———– | ———– | ———– |———– |———– | | VPC-Eduard | 10.2.0.0/16 | 10.2.1.0/24 | IGW-Eduard | RT-Eduard | 884365647459 | vpc-099d2ee5027493805 | srv1 | | VPC-Alejandro | 10.0.0.0/16 | 10.0.1.0/24 | IGW-Alejandro | RT-Alejandro | 138706074330 | vpc-0d684a2cca2a773db | srv2 | | VPC-Linyi | 10.1.0.0/16 | 10.1.1.0/24 | IGW-Linyi | RT-Linyi | 058264113592 | vpc-0e802896fad67ad98 | srv3 | | VPC-Carlos | 10.3.0.0/16 | 10.3.1.0/24 | IGW-Carlos | RT-Carlos | 946111168272 | vpc-069ea527c0d5e8f0e | srv4 |
| Servidor | Servicios | Tipo EC2 |
|---|---|---|
| 1 | ElasticSearch, Kibana, Nagios | t2.large |
| 2 | Web, Audio, Streaming | t3.small |
| 3 | DNS, FTP | t2.micro |
| 4 | Base de Datos (PGSQL) | t3.small |
| 5 | Copias de Seguridad | t2.micro |
La preparación para la creación y conectividad de los servidores es lo siguiente:
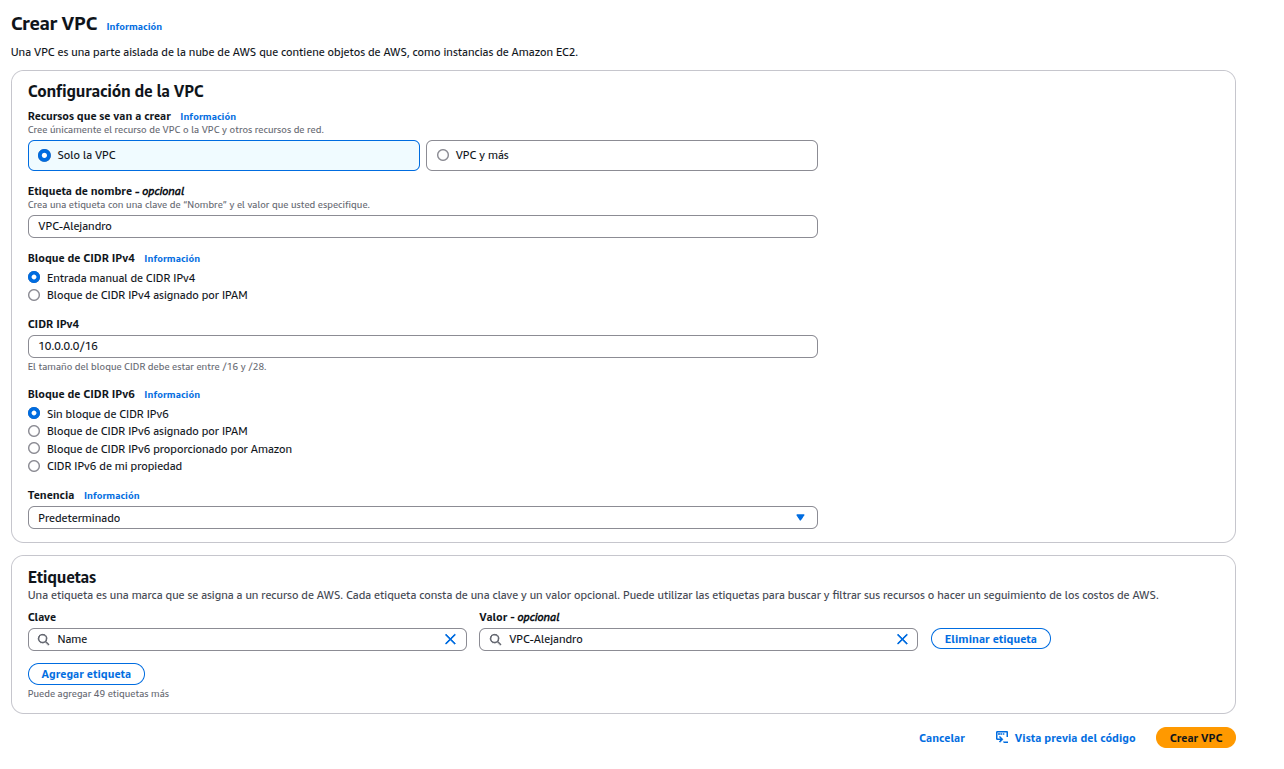
Crear una VPC (Virtual Private Cloud), sirve para tener una red privada virtual dentro de AWS donde se desplegará las instancias.
Asignar un nombre a la VPC y el rango de IP privadas.
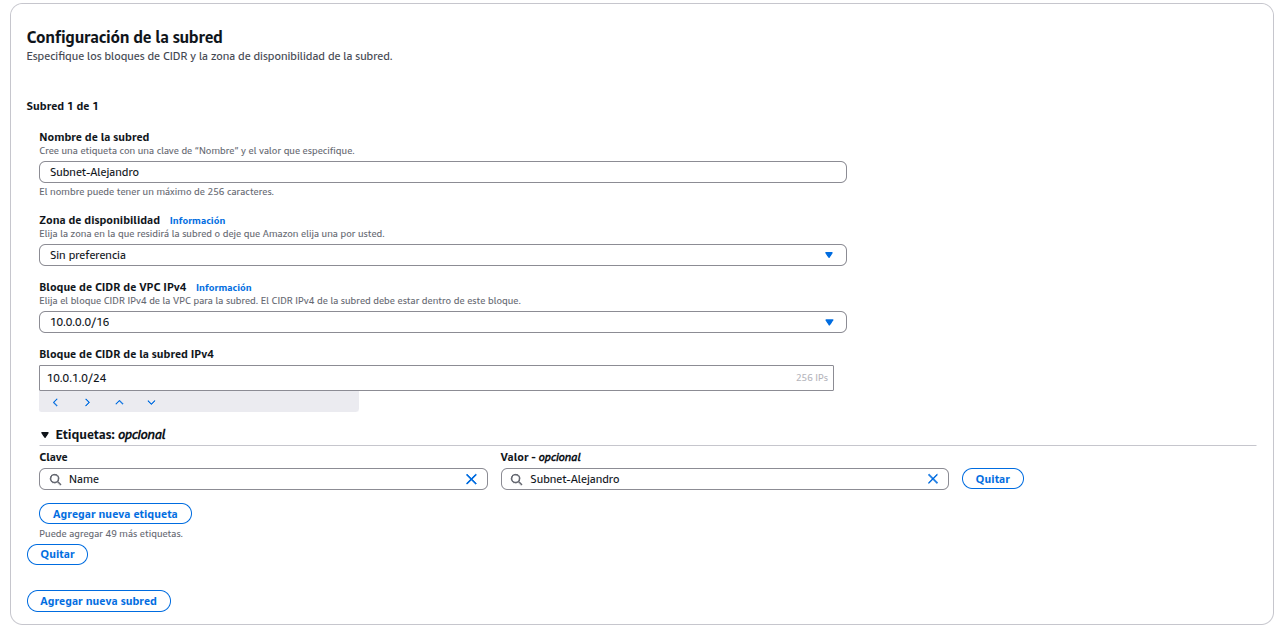
Configurar una subred, es una sección de la VPC donde se puede lanzar recursos como instancias EC2, bases de datos, etc. Cada subred tiene un rango de direcciones IP definido y puede ser pública o privada, dependiendo de si tiene acceso a Internet.
Seleccionar la VPC que se ha creado en el apartado anterior, asignar un nombre a la subred, el rango de direcciones IP privadas y la zona tiene que ser la misma que se usa para EC2.
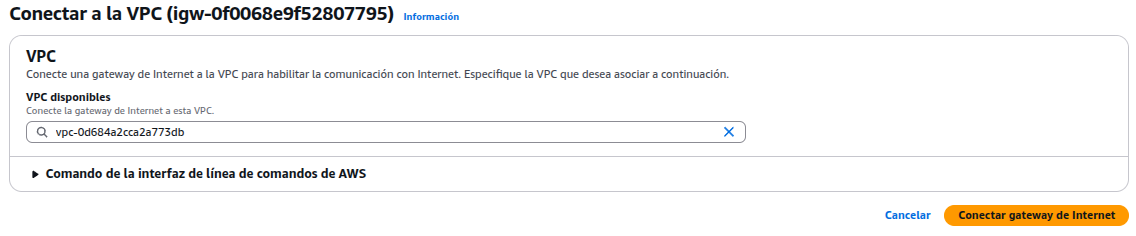
Crear Internet Gateway, sirve para dar acceso a Internet a los recursos dentro de una VPC, como por ejemplo, una instancia EC2 que quiere que actúe como un servidor web accesible desde fuera de AWS. Es un componente de red que conecta la VPC a Internet. Funciona como un “puente” entre la red privada en AWS y la red pública (Internet).
Asignar un nombre al IGW, una vez creado, haz clic en “Acciones > Conectar a la VPC” y seleccionar la VPC.

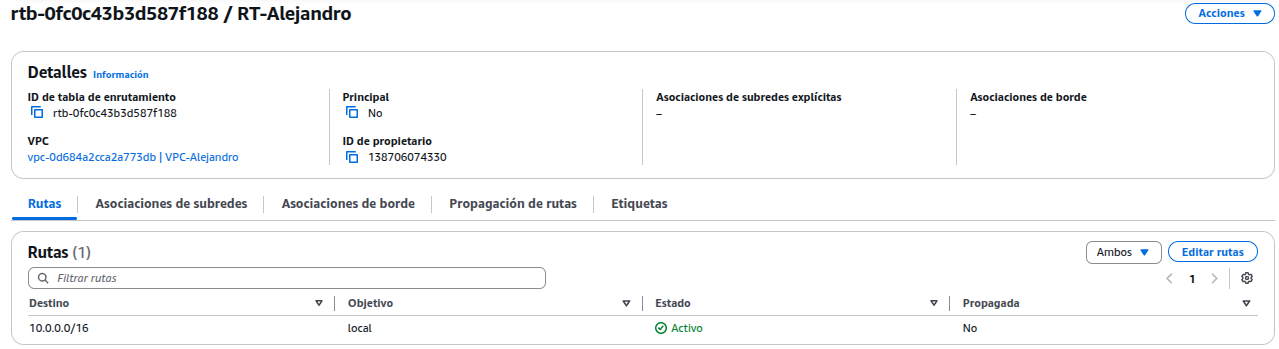
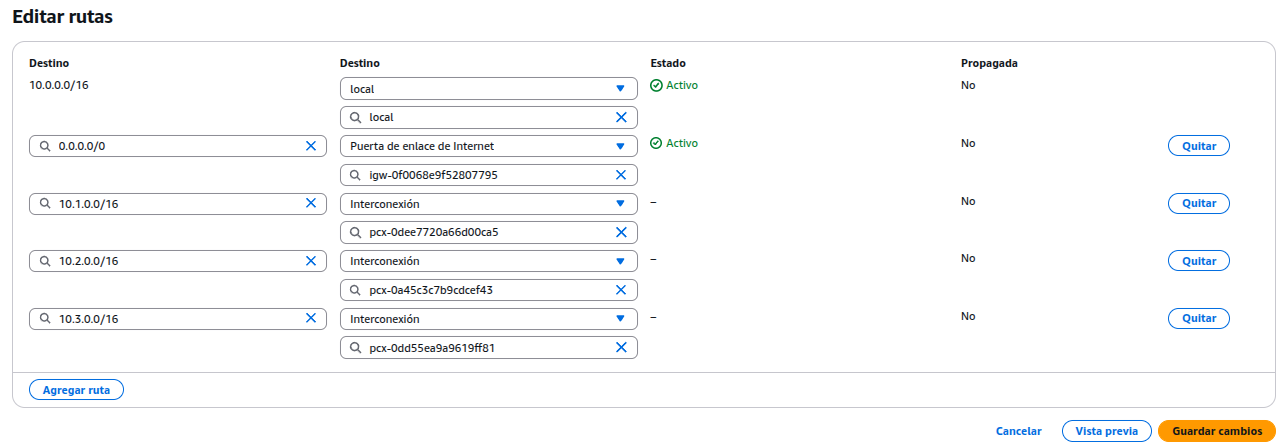
Crear una tabla de enrutamiento, sirve para controlar cómo se dirige el tráfico dentro de la VPC, una lista de reglas que le dice a los recursos en una subred a qué destino deben enviar el tráfico y por qué medio.
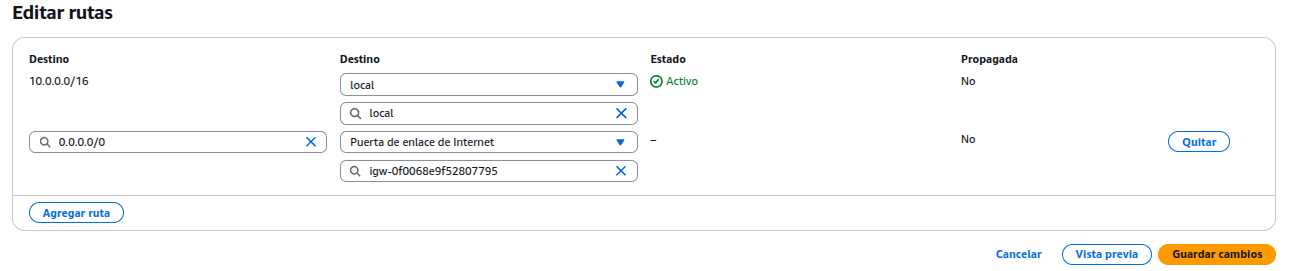
Asignar un nombre y seleccionar la VPC. Luego, ir a la pestaña “Rutas” > Editar rutas y añadir una nueva ruta. Destino: 0.0.0.0/0 Destino → Gateway: selecciona el Internet Gateway creado.
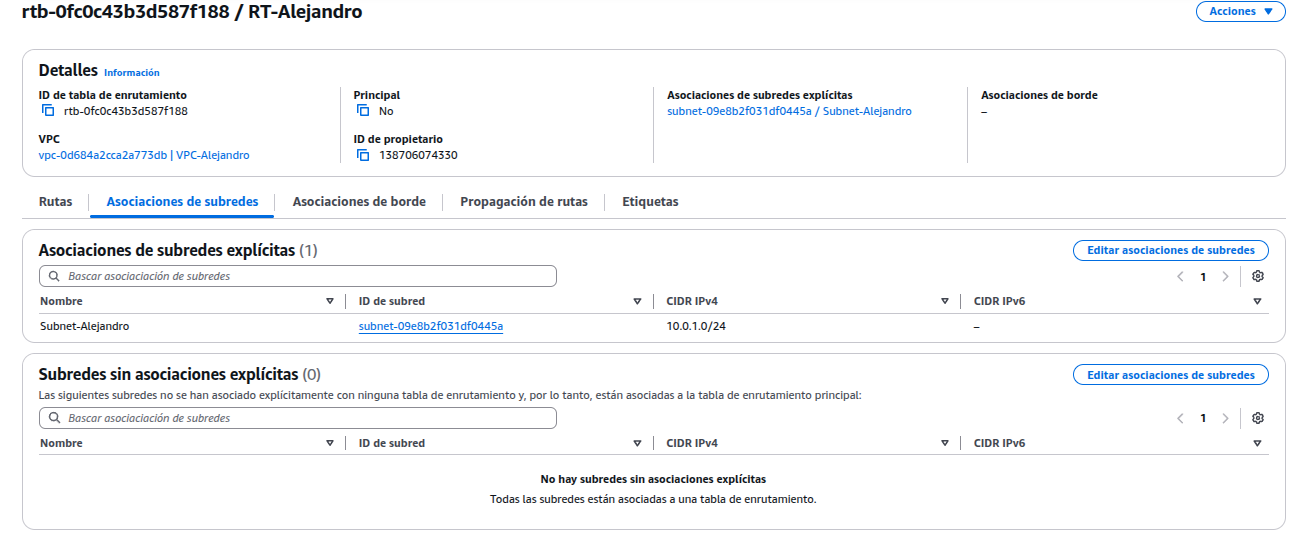
Ir a la pestaña “Asociaciones de subredes” y asociar la subred. Esto permite que todas las IPs externas puedan comunicarse con las instancias.
Crear un grupo de seguridad, sirve para controlar qué tráfico de red puede entrar o salir de las instancias, como una especie de firewall virtual a nivel de instancia.
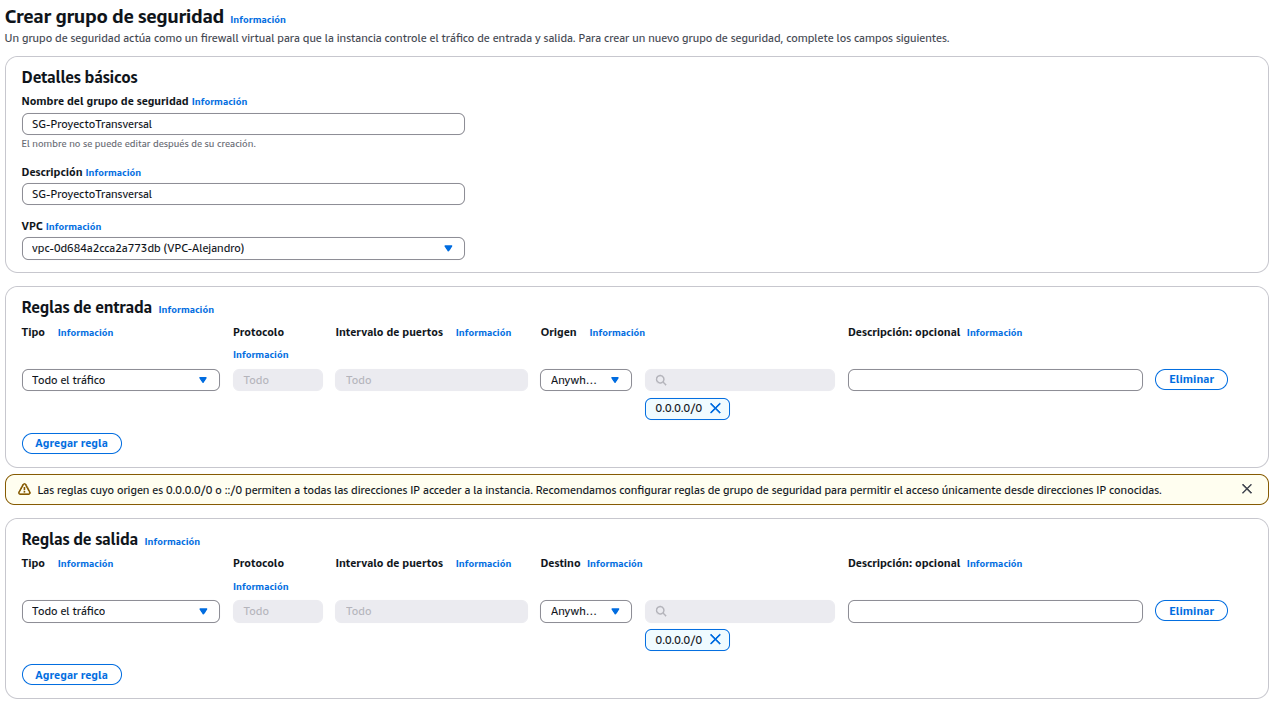
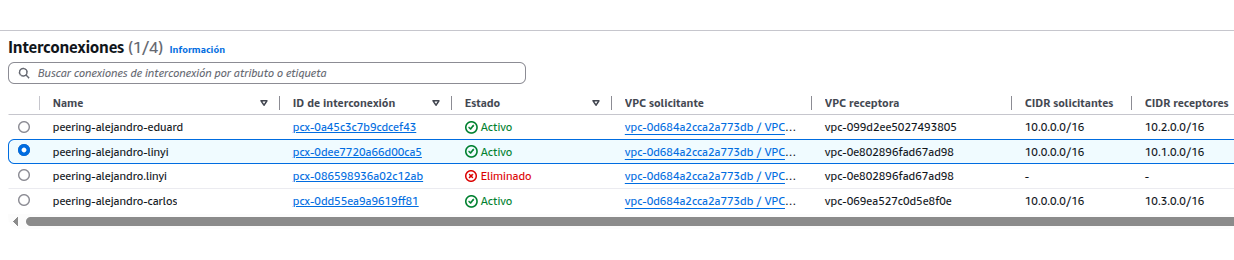
Interconexión entre instancias, sirve para comunicar distintas redes o entornos entre sí, ya sea dentro de AWS o entre AWS y una red externa. Estas interconexiones permiten compartir datos, servicios o acceder de forma privada y segura entre distintos recursos o ubicaciones.
Conectar las instancias dentro de la VPC usando sus IPs privadas.
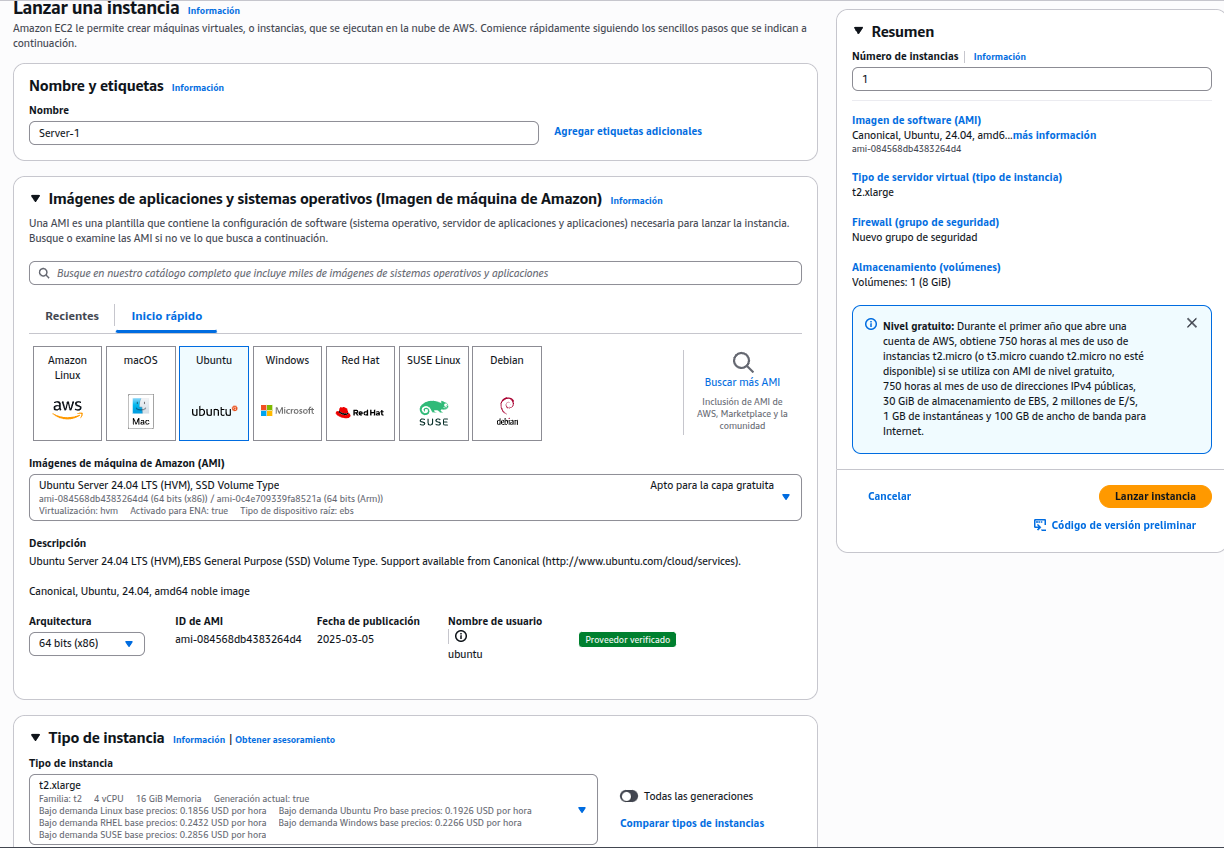
Configuración de Servidor 1
Se crea una instancia de tipo t2.large con sistema operativo Ubuntu Server 24.04.
Se añade un disco de 32GB, porque Elasticsearch requiere espacio suficiente para operar correctamente.
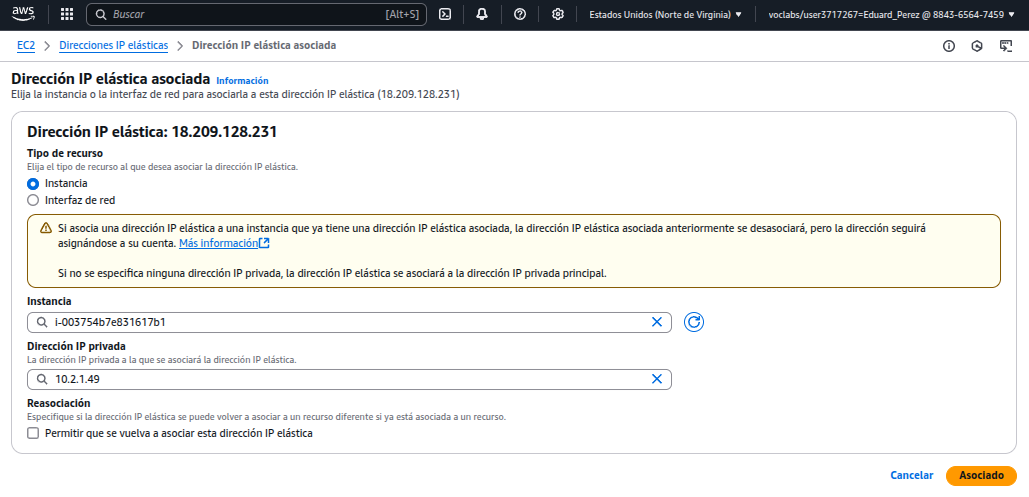
Se asigna una IP elástica, es una IP pública estática.
Se accede a la instancia mediante la clave privada por SSH.

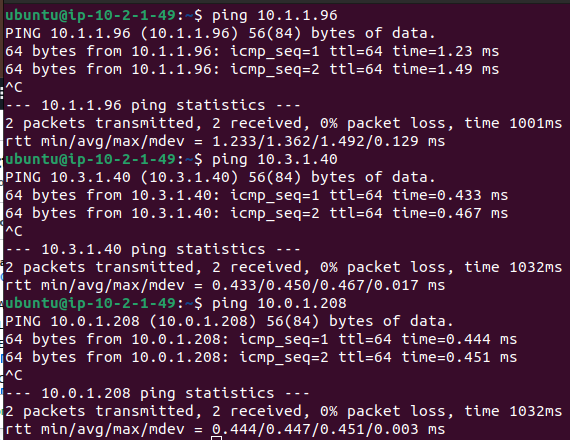
Se hace un ping a los otros servidores para verificar la conectividad.
ElasticSearch + Kibana
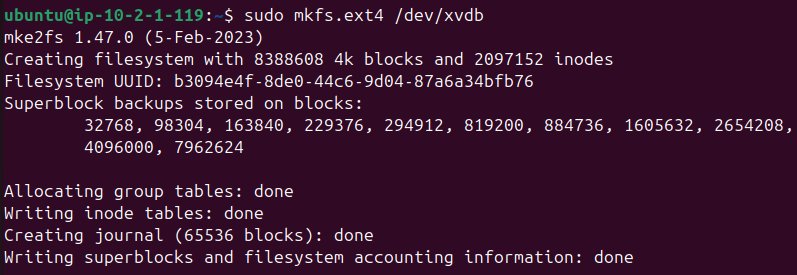
Se formatea por completo el disco de 32 GB (/dev/xvdb) como ext4.
Se crea un directorio /opt y eliminar todo su contenido para usarlo como punto de montaje limpio.

Se monta la partición recién formateada sobre /opt, de modo que cualquier dato escrito en este directorio, residirá en el volumen de 32 GB.

Configurar el archivo /etc/fstab, es un archivo de configuración en Linux que define cómo y dónde se montan de forma automática los sistemas de archivos (como discos, particiones o recursos remotos) durante el arranque del sistema sin tener que hacerlo manualmente cada vez. La configuración dice “monta siempre este disco (con UUID) en /opt con ext4 al arrancar” el sistema.

Con la comanda df -h se puede mostrar que /dev/xvdb aparece montado en /opt con 32 GB de memoria, como se puede observar, ha tenido éxito el montaje
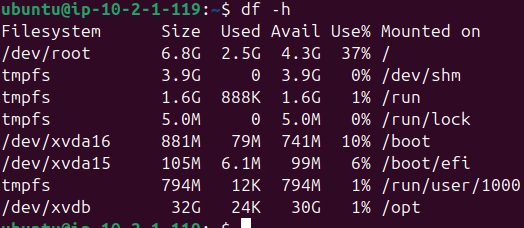
Se ha creado el usuario elastic, se le asigna una shell Bash, una contraseña y se añade al grupo sudo para que el usuario pueda realizar tareas que requieren permisos elevados, como modificar archivos del sistema o gestionar servicios.


Se crean dos directorios para la instalación, uno para el servicio ElasticSearch y el otro para Kibana. Comanda: mkdir /opt/elastic /opt/kibana

Se asigna al usuario elastic como usuario y grupo propietario de los directorios creados en el apartado anterior. Lo hace recursivamente, es decir, aplica el cambio a todas las subcarpetas y archivos dentro de /opt/elastic y /opt/kibana.

Entrar al directorio /opt/elastic y descargar Elasticsearch 9.0.1 con la siguiente comanda
sudo wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.17.4-linux-x86_64.tar.gz

El mismo proceso con Kibana. sudo wget https://artifacts.elastic.co/downloads/kibana/kibana-8.17.4-linux-x86_64.tar.gz

A continuación, descomprimir el archivo .tar.gz dentro del directorio, utilizando la comanda tar xvf.

Utilizar la comanda chown -R elastic:elastic para asignar la propiedad al directorio, de modo que el usuario elastic tendrá control total sobre la carpeta y su contenido.

Iniciar con el usuario elastic y ejecutar la comanda ./bin/elasticsearch desde dentro del directorio donde se había descomprimido Elasticsearch. En el proceso de arranque da la información para conectar Kibana.

IMPORTANTE: Guardar contraseña usuario elastic, HTTP CA certificate fingerprint y enrollment token porque hará falta después para acceder a la aplicación Web.
✅ Elasticsearch security features have been automatically configured!
✅ Authentication is enabled and cluster connections are encrypted.
ℹ️ Password for the elastic user (reset with bin/elasticsearch-reset-password -u elastic):
0=7ohiqMIMy=tsDVFie9
ℹ️ HTTP CA certificate SHA-256 fingerprint: 87f4438412e1ef8616d6e29a4bc274b3ea87b203297504302e13164290187ab9
ℹ️ Configure Kibana to use this cluster: • Run Kibana and click the configuration link in the terminal when Kibana starts. • Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes): eyJ2ZXIiOiI4LjE0LjAiLCJhZHIiOlsiMTAuMi4xLjExOTo5MjAwIl0sImZnciI6Ijg3ZjQ0Mzg0MTJlMWVmODYxNmQ2ZTI5YTRiYzI3NGIzZWE4N2IyMDMyOTc1MDQzMDJlMTMxNjQyOTAxODdhYjkiLCJrZXkiOiJ3cjVQRHBjQlVyeHBFZTNJYm1mejpqRGhSc2c0ZFV2YVhrck9Zd0JiMnNBIn0=
ℹ️ Configure other nodes to join this cluster:
• On this node:
⁃ Create an enrollment token with bin/elasticsearch-create-enrollment-token -s node.
⁃ Uncomment the transport.host setting at the end of config/elasticsearch.yml.
⁃ Restart Elasticsearch.
• On other nodes:
⁃ Start Elasticsearch with bin/elasticsearch --enrollment-token <token>, using the enrollment token that you generated.
Encriptedkey: zS7myWkXIFI98brFoojXzHu7bOu1kzjmbTvtsv/aJvc=
Modificar el archivo de configuración /opt/elastic/elasticsearch-9.0.1/config/elasticsearch.yml descomentar network.host, define a qué direcciones IP escucha Elasticsearch para aceptar conexiones; y http.port, establece el puerto (como 9200) para recibir peticiones HTTP.
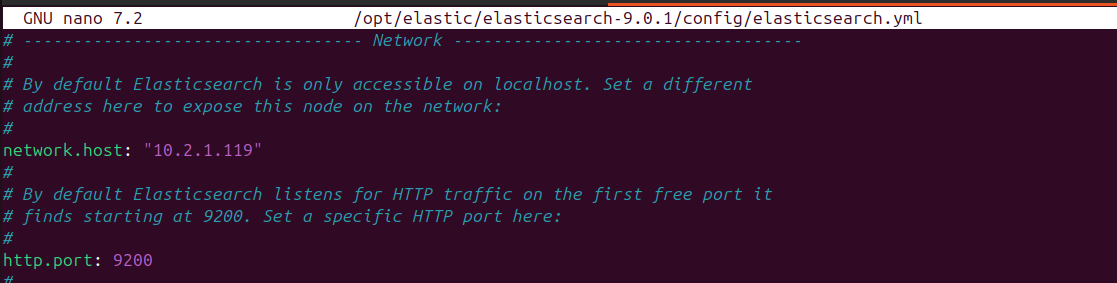
En el caso de Kibana, al igual que Elastic, para configurar hay que descomentar, network.host y http.port en el archivo de configuración kibana.yml.
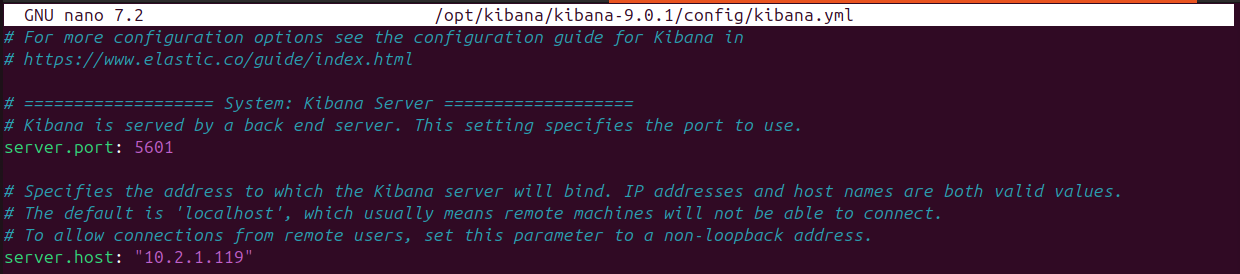
Anotar la clave que usarán los Encrypted Saved Objects

Ejecutar Elasticsearch: ./bin/elasticsearch

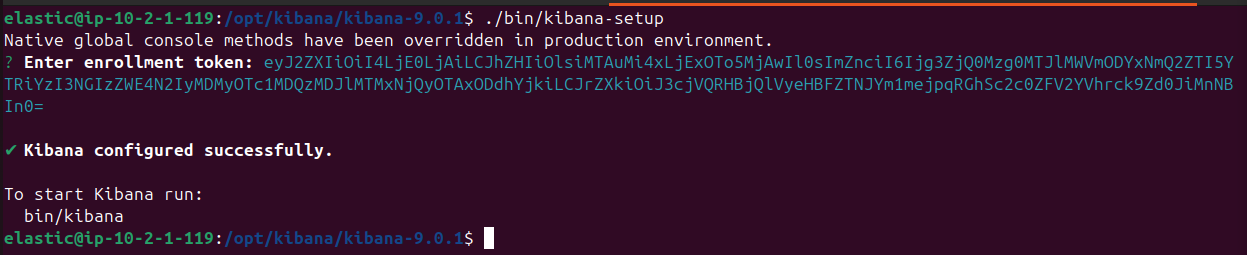
Ejecutar Kibana, ./bin/kibana-setup. Introducir el enrollment token que se había copiado y muestra el mensaje de éxito (“Kibana configured successfully”), junto con la indicación de que a partir de ahora, para arrancar Kibana ejecutar bin/kibana.
Abrir en el navegador la URL de Kibana (http://34.202.92.100:5601) , aparecerá la pantalla de bienvenida y autenticación. Introducir el Username (elastic) y la Password que se generó al arrancar Elasticsearch. De esta manera, se accede al dashboard principal de Kibana.
Auditbeat
Se crea la carpeta para Auditbeat, mkdir /opt/audibeat en la partición de 32GB.

A continuación descargar archivo .tar.gz oficial de Auditbeat 9.0.1 con la comanda sudo wget https://artifacts.elastic.co/downloads/beats/auditbeat/auditbeat-8.17.4-linux-x86_64.tar.gz

Una vez completada la descarga, descomprimir auditbeat-9.0.1-linux-x86_64.tar.gz en ese mismo directorio.

Nagios
Se crea el usuario “nagios”.

Se prepara el punto de montaje, se crea la carpeta /usr/local/nagios que servirá de directorio raíz para Nagios.

Se monta la partición (en este caso /dev/xvdc) dentro de ese directorio, para dedicar un disco separado al servicio.

Iniciar como el usuario Nagios.

Se crea el directorio de fuentes y se ajustan los permisos. Dentro del montaje, se crea la carpeta /src, donde se descargará y se compilará ???? el código fuente de Nagios. También se asegura que el usuario Nagios sea el propietario del directorio, para que tenga derechos de escritura y ejecución durante la compilación.

Se descarga el código fuente de Nagios Core, se ejecuta wget sobre el enlace oficial de Nagios 4.5.9 y se guarda directamente con el nombre nagios-4.5.9.tar.gz.
Se descomprime el paquete.

Se instala la utilidad unzip para que el sistema pueda descomprimir los plugins necesarios.

Ahora, dentro del directorio de fuentes de Nagios, se ejecuta el lanzador de configuración, se comprueba que se tengan gcc, make, strip y demás utilidades, y se crean unos archivos de ejemplo en sample-config/.
Se continúa con la compilación e instalación completa de Nagios, se compila todo el código fuente.
Se instalan los binarios y scripts.
– Se copia el ejecutable nagios a /usr/local/nagios/bin/.
– También se instalan los scripts de control en /usr/local/nagios/libexec/ y las bibliotecas necesarias.

Se instala el servicio en systemd.

Se instalan los archivos de configuración por defecto.
– Se copian los archivos de configuración desde sample-config/ a /usr/local/nagios/etc/.
– Se incluyen nagios.cfg, resource.cfg, y el directorio objects/ con localhost.cfg, commands.cfg y services.cfg.

Se crea y se asegura el directorio de comandos externos.

Se configura la interfaz web en Apache:
– Se copia htpasswd.conf (configuración de autenticación) a /etc/apache2/sites-available/nagios.conf.
– Se crea el enlace simbólico en sites-enabled/.
– Con esto, Apache servirá la URL http://34.202.92.100/nagios/ y se exigirán credenciales para acceder.
Usuario: Nagiosadmin
Contraseña: @ITB2024

Se crea el usuario nagiosadmin para la interfaz web mencionada anteriormente.

Después compruebo los permisos:

Se verifica la configuración de los CGIs de Nagios: Se abre el archivo de ejemplo cgi.cfg para asegurarse de que:
Se apunta al main_config_file=/usr/local/nagios/etc/nagios.cfg.
Se tienen bien definidos los ficheros de caché.
Se habilita el módulo CGI en Apache y se reinicia el servicio.

Se habilita el sitio de Nagios en Apache.

Se recarga la configuración de Apache.

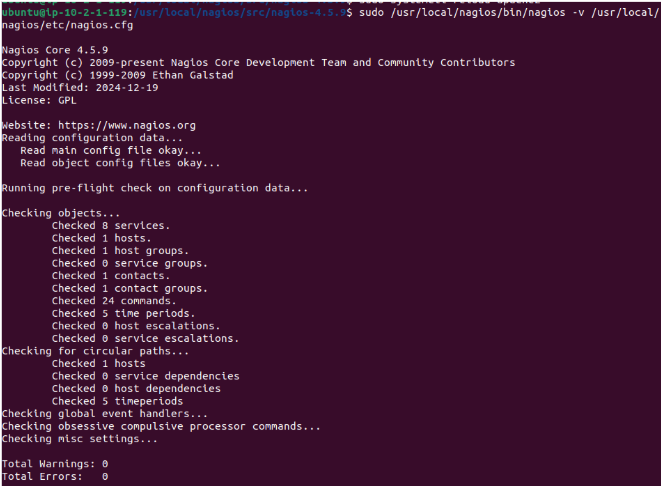
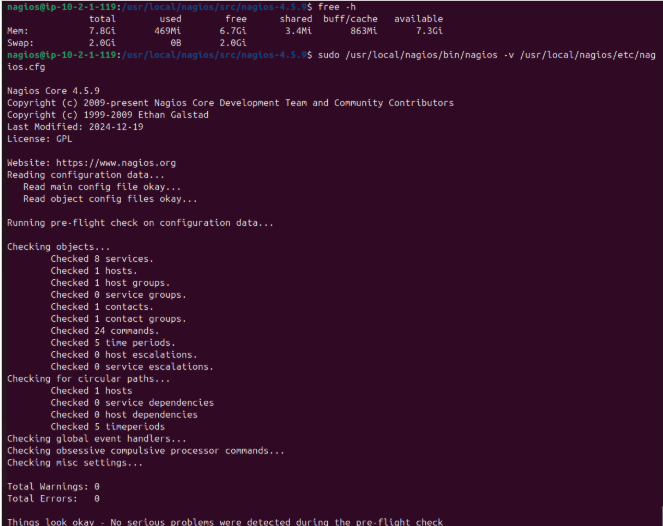
Se ejecuta la comprobación previa de Nagios.
Ahora, se accede a la interfaz web de Nagios para verificar el estado y, a continuación, se instalan los plugins y se prepara el directorio de comprobaciones remotas:
Se comprueba la interfaz web.
Se abre http://34.202.92.100/nagios/ en el navegador.
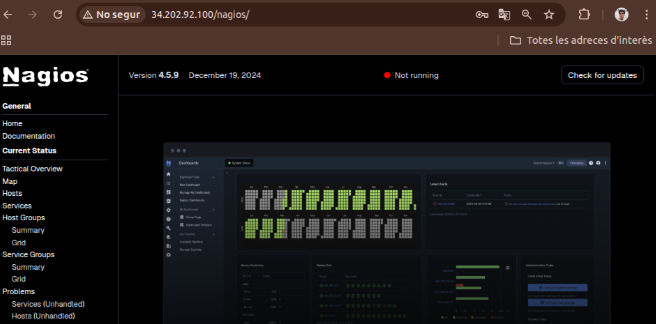
En “Current Status” se observa que todos los hosts y servicios aparecen como CRITICAL (sin haber sido iniciados ni configurados del todo aún).
Activación de servicios:
Se instalan los paquetes de plugins.

Se prepara el directorio de plugins de Nagios.

Se enlazan todos los plugins disponibles.

Se ajustan permisos y propietario:
– Se asigna nagios:nagcmd como usuario y grupo para que el demonio y el daemon externo puedan invocarlos.
– Se establecen permisos rwx r-x — para seguridad.

Se crea un swapfile de 2 GB.

Se reservan 2 GB en /swapfile y se protege con permisos (rw——-).

Se inicializa el swap:
– El sistema avisa de que había una firma antigua (quizá de una prueba previa), la limpia y crea la nueva.

Se vuelve a formatear (doble mkswap, idéntico a la captura).

-Se verifica memoria y swap.
-Se ejecuta la comprobación previa de Nagios.
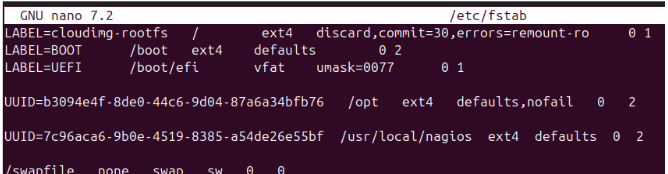
Se hace persistente el swap en el arranque.
– Se abre /etc/fstab con un editor y se añade esta línea al final:
Se recarga el servicio de Nagios.

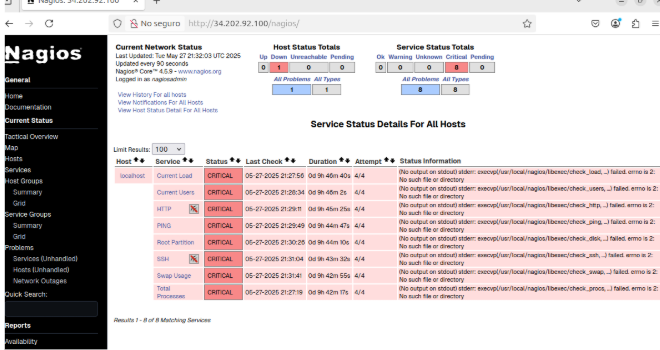
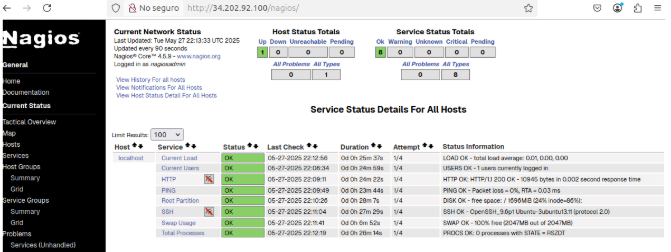
Se accede de nuevo a http://34.202.92.100/nagios/ y esto es lo que se observa: Current Network Status
– El panel muestra “Current Network Status” con todos los contadores a cero y el círculo verde, lo que indica que Nagios está ejecutándose y se están recopilando datos correctamente. Host Status Totals
– Hay 1 host monitorizado (el propio localhost), marcado como Up. Service Status Totals
– De los servicios configurados, todos están en OK (0 warnings, 0 criticals, 0 unknown).
Detalle de cada servicio
Hosts: SRV1
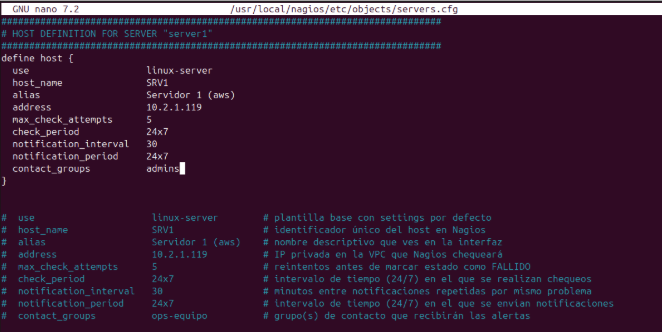
Se define en servers.cfg el host SRV1 con la plantilla linux-server, especificando nombre, alias, dirección IP, periodos de chequeo y notificación, intentos máximos y grupo de contactos.
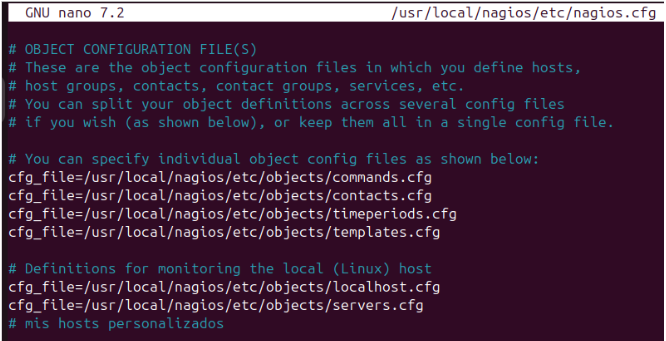
Se incluye en nagios.cfg el fichero:
cfg_file=/usr/local/nagios/etc/objects/servers.cfg
Para cargar las definiciones de hosts personalizados.
Se comprueba la configuración
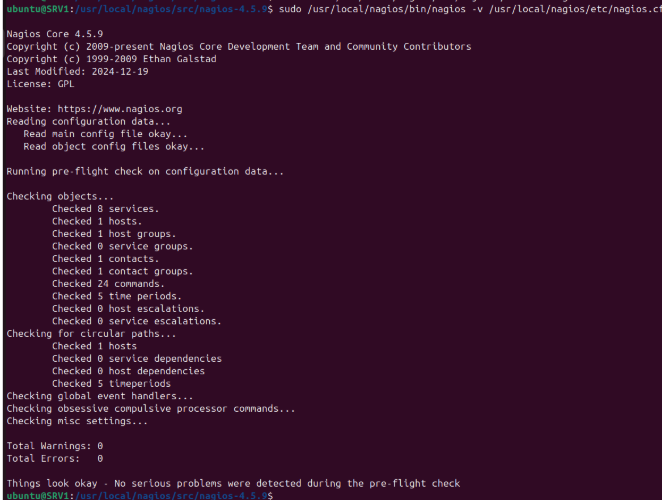
Se resetea

Y ya se muestran mis hosts personalizados, en este caso SRV1.
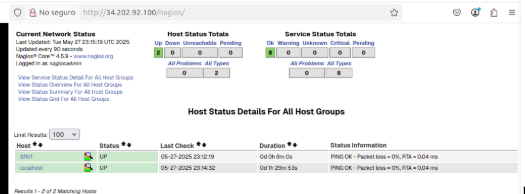
Ejemplo para SRV1
En nagios.cfg se hace lo siguiente para SRV1: Se añade el archivo de servicios para SRV1; en este fichero se enlazará cada servicio (PING, HTTP, SSH, disco, swap…) al host SRV1, indicando qué comandos de verificación se usarán y con qué umbrales.
Ahora, para SRV1 se ha abierto el fichero services.cfg y se ha creado un bloque define service por cada chequeo que se desea monitorizar. En cada uno de los servicios se especifica: PING Uso de disco / Usuarios conectados Procesos críticos Swap Usage
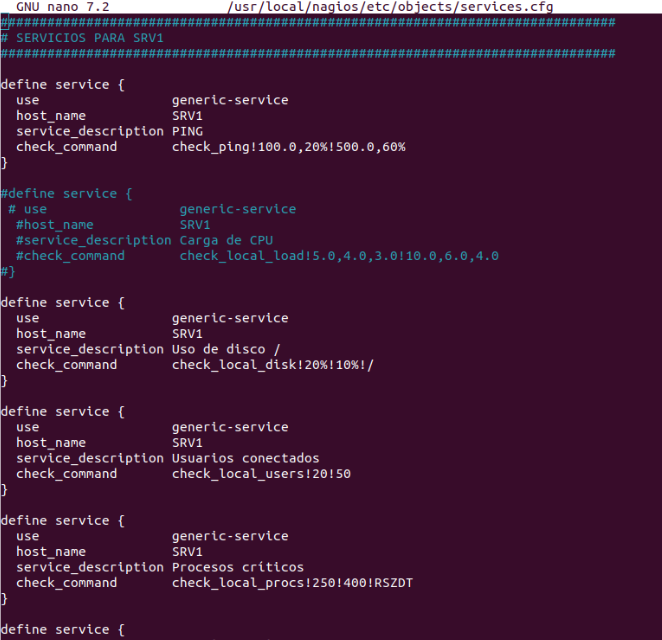
En commands.cfg se han definido los comandos personalizados que luego se enlazan en cada servicio de SRV1. De este modo, basta con que se le pasen argumentos genéricos (ej.: ARG1, ARG2) y se ejecutan los checks contra el plugin adecuado. Así se tienen configurados: check_local_disk check_local_procs check_local_users check_local_swap check_local_mrtgtraf
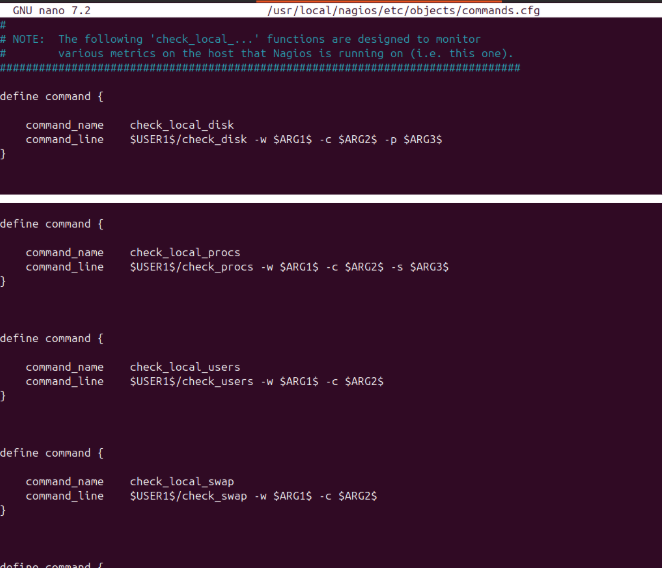
En el fichero localhost.cfg se definen los servicios que se monitorizarán sobre el propio servidor Nagios (localhost): Root Partition Current Users Total Processes Swap Usage SSH HTTP
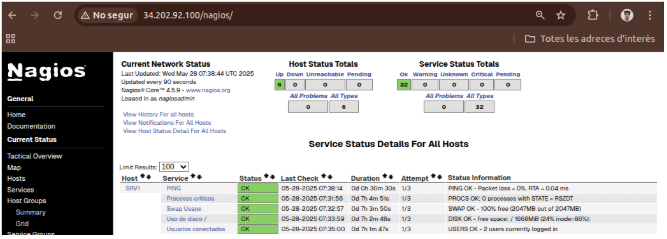
En estas capturas se muestra cómo aparecen en la interfaz web de Nagios los servicios configurados para SRV1 y el detalle de uno de ellos (“Usuarios conectados”): Listado de servicios de SRV1 En “Service Status Details For All Hosts” se filtra por SRV1 y se observan los cinco checks definidos:
-PING — OK: se indica que la latencia se encuentra dentro de los umbrales.
-Procesos críticos — OK: se indica que el número de procesos se encuentra en rango.
-Swap Usage — OK: se indica que el uso de swap se mantiene bajo el umbral.
-Uso de disco / — OK: se indica que el espacio en la partición raíz es suficiente.
Cada fila muestra la última hora de ejecución, duración del chequeo y el estado.
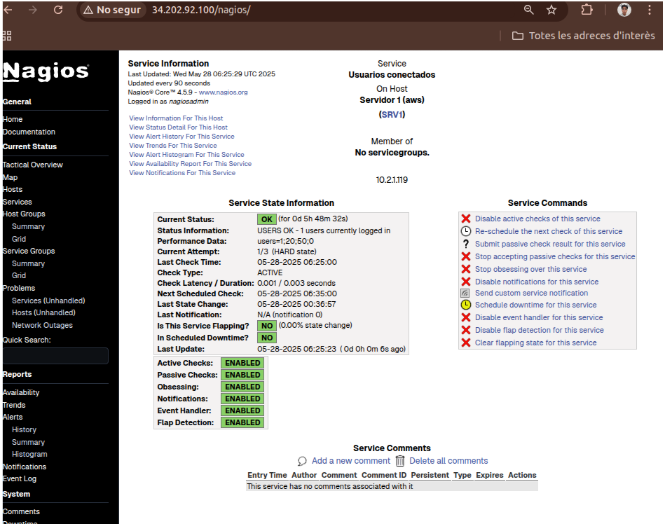
Se hace la prueba entrando en un usuario:

Se mira si me he conectado con el usuario.
Configuración de Servidor 2
Primero se crea una instancia dentro de AWS (Amazon Web Service) que tendrá el sistema operativo Ubuntu Server 24.04 LTS, se asigna t3.small como tipo de instancia dado que nos permitirá gestionar los servidores web, audio y streaming.
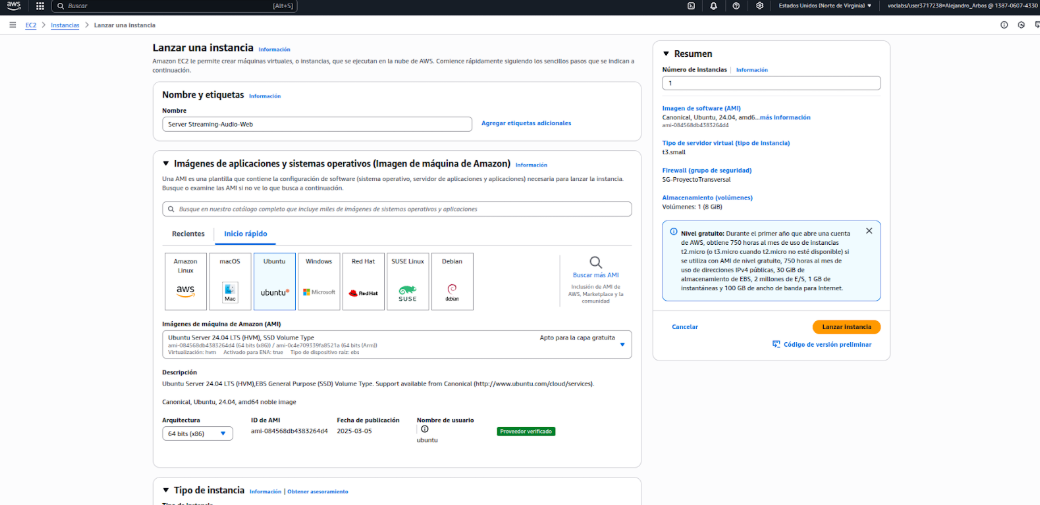
Seguidamente, se asigna una IP elástica, que es una dirección IP pública fija que se puede reasignar entre distintos servidores para mantener accesible el servicio incluso si cambia la infraestructura.
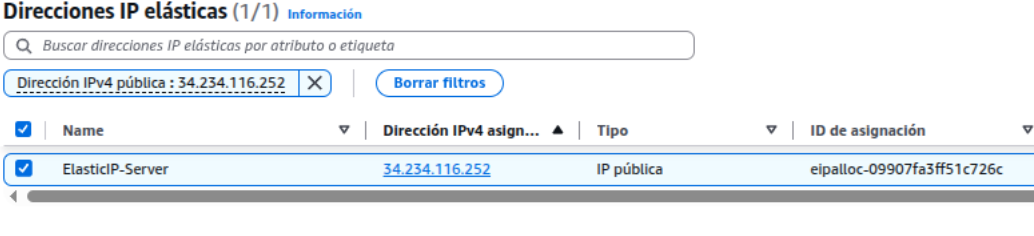
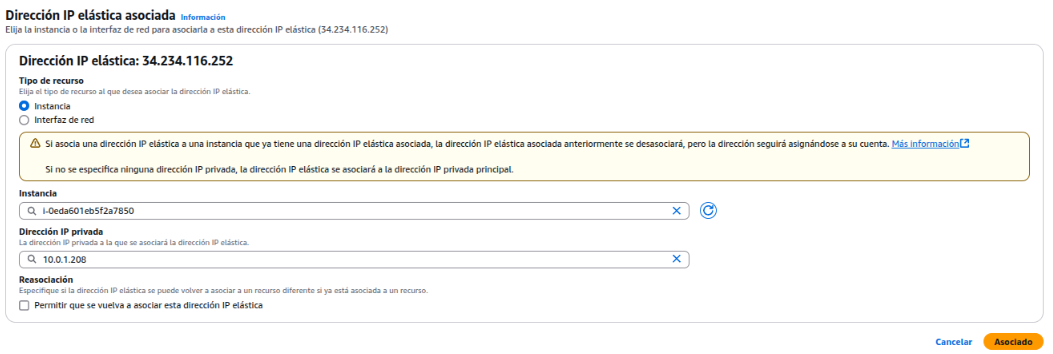
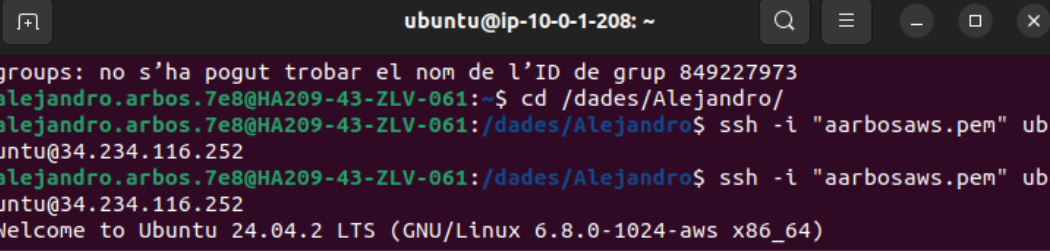
Después de la creación de la instancia, se hacen pruebas de conectividad con los otros servidores.
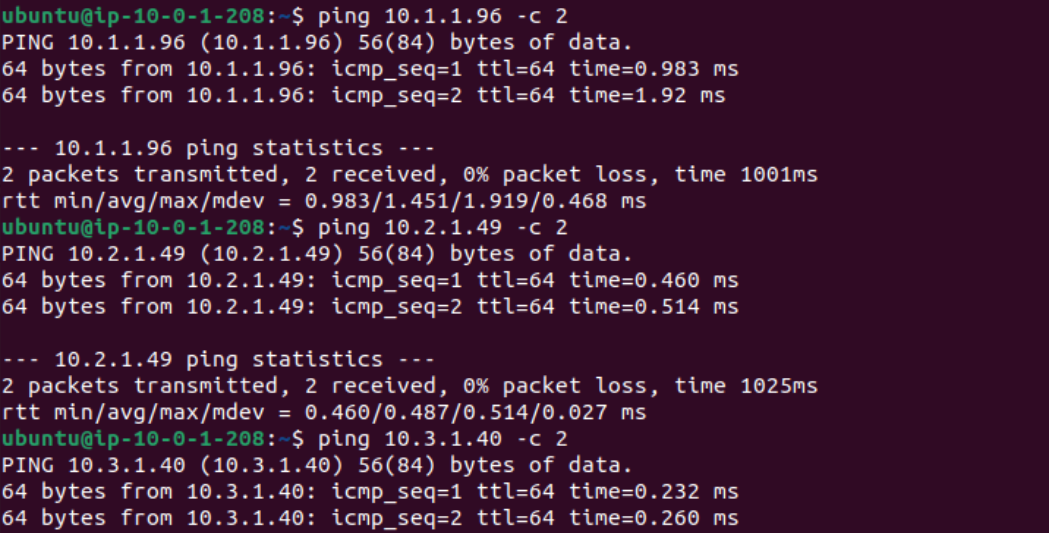
Se cambia el nombre de la instancia.

Web (Nginx)
Nginx es un servidor web de alto rendimiento que también puede funcionar como proxy inverso y servidor de medios. Se utiliza para servir páginas web, redirigir tráfico y gestionar transmisiones de audio o vídeo.
Para poder instalar este servicio se debe de ejecutar el comando “sudo apt install nginx” y “systemctl status nginx” para comprobar su estado.
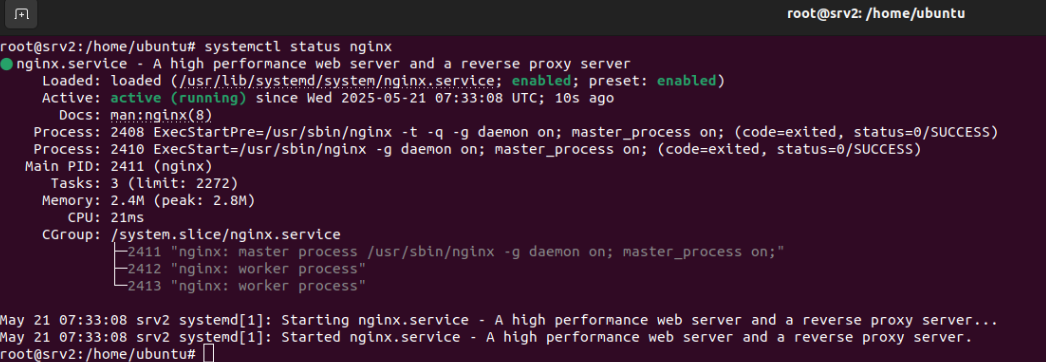
Se crea un directorio para guardar los archivos relacionados con nuestra página principal. Además, se ha instalado la plantilla Massively con “wget”.
Para garantizar la seguridad de nuestra página web, se han generado tres archivos clave utilizando la herramienta OpenSSL. Estos archivos se utilizan para configurar un certificado SSL en nuestro servidor Nginx, asegurando que las comunicaciones con la página sean seguras y cifradas.
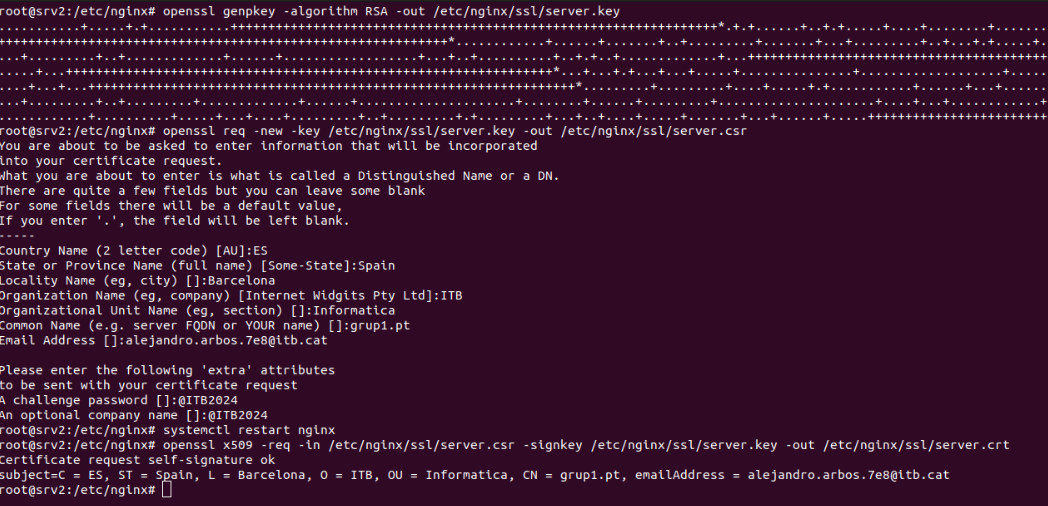
Se crea y configura el host virtual dentro del directorio /etc/nginx/sites-available con los siguientes parámetros:
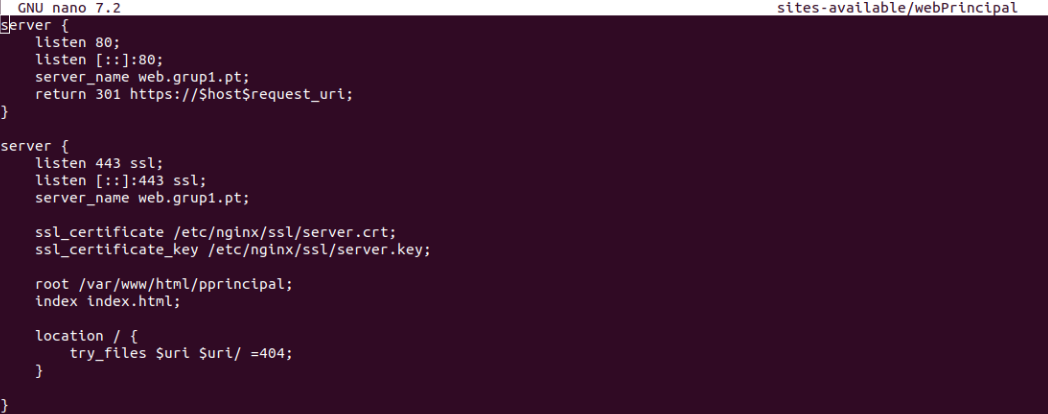
Al recibir una petición por el puerto 80, redirige automáticamente al puerto 443 (HTTPS), nuestro servidor escucha por todas las interfaces, por ende, se puede ver tanto con su IP privada y pública. Se añaden los certificados creados anteriormente, ruta de archivos, index.html y un return 404 para otros errores.
Para acceder a la página web: https://18.204.111.82/

WEB FTP
Además de la página anterior, se ha configurado el servicio FTP para poder usarlo a través de nuestra web.
Se crea un nuevo directorio “ftp” dentro de “/var/www/html/pprincipal” en el cual se añade el archivo descomprimido de monsta_ftp. Monsta FTP es un cliente FTP basado en web, desarrollado en PHP y AJAX, que puede utilizar para administrar su sitio web a través de su navegador, editar código, cargar y descargar archivos, copiar/mover/eliminar archivos y carpetas, todo sin instalar ningún software de escritorio.
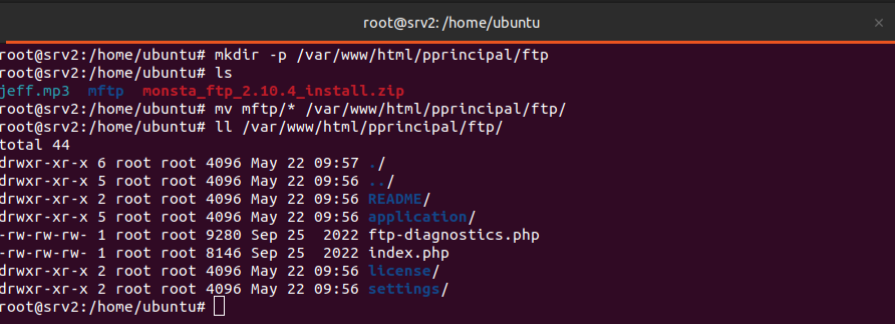
Lo más probable es que muestre el siguiente error:
“2025-05-21T09:46:43.211693+00:00 srv3 sshd[10412]: Unable to negotiate with 34.234.116.252 port 44862: no matching host key type found. Their offer: ssh-rsa,ssh-dss [preauth]”
Este error significa que el cliente (en la dirección IP 34.234.116.252, puerto 44862) intentó conectarse al servidor, pero no se pudo negociar una conexión SSH porque el cliente ofreció tipos de claves de host (ssh-rsa, ssh-dss) que el servidor no acepta.
Para solucionar el error, se debe agregar las siguientes 2 líneas dentro del archivo /etc/ssh/sshd_config
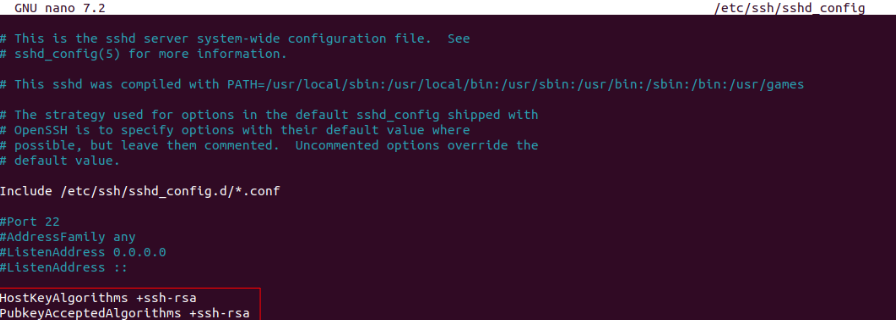
Se modifica nuestro host virtual para poder acceder a la nueva localización /ftp y activar el uso de php-8.3.
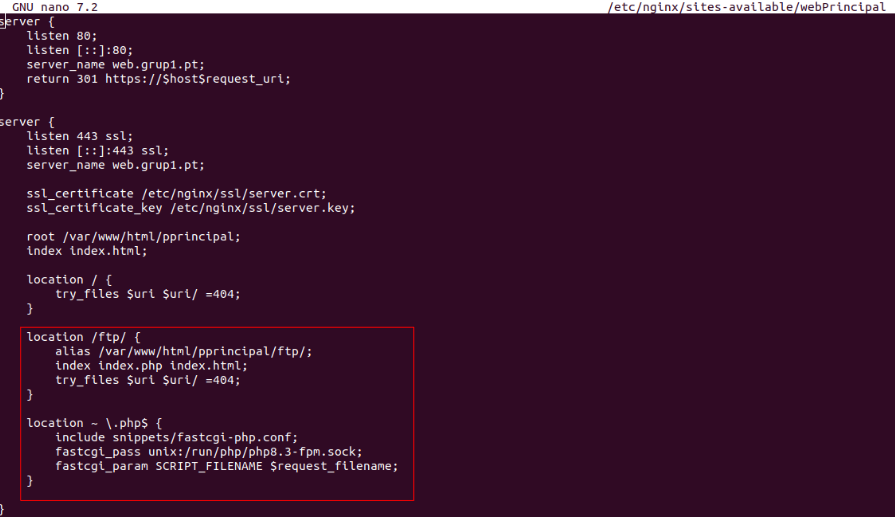
Para poder acceder a Monsta FTP, debemos navegar por “http://URLweb/ftp”. Una vez dentro, se puede autentificar el usuario tanto por FTP como SFTP/SCP.

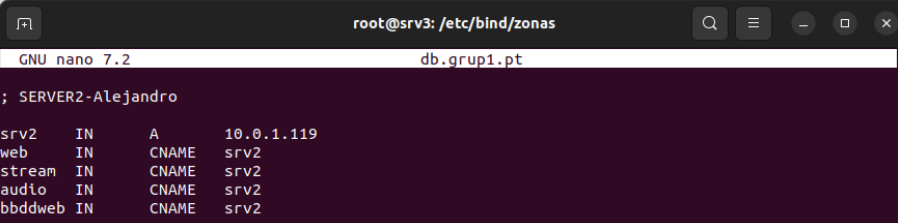
Se crea un host virtual que hará de proxy para poder mostrar una página del servidor 4 que tiene las tablas sobre Auditoría de Empleados por Convenio. Para hacer esto, se debe añadir al archivo de configuración bind9 que contiene las zonas directas un nuevo CNAME para que haga referencia al proxy y poder acceder como bbddweb.grup1.pt.
Estos cambios y búsqueda/resolución de nombre solo se pueden ver desde dentro de la red virtual privada.
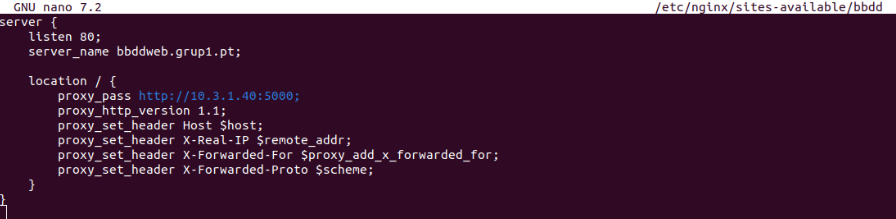
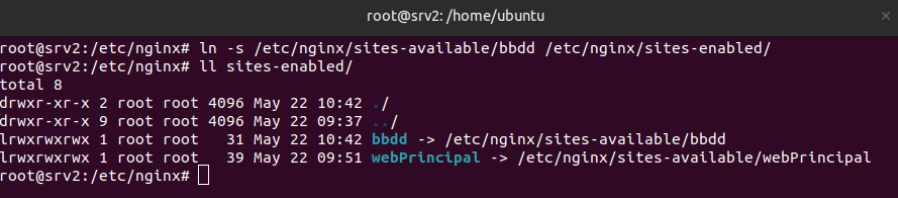
Se crea un enlace simbólico del fichero “bbdd” que está dentro del directorio /etc/nginx/sites-available/ con /etc/nginx/sites-enabled/ para activar el host virtual que actúa como proxy.
Audio
Icecast es un servicio de streaming de audio en tiempo real que permite transmitir contenido multimedia a múltiples usuarios simultáneamente. Se utiliza principalmente para crear emisoras de radio por internet o para enviar audio en directo a través de la red.
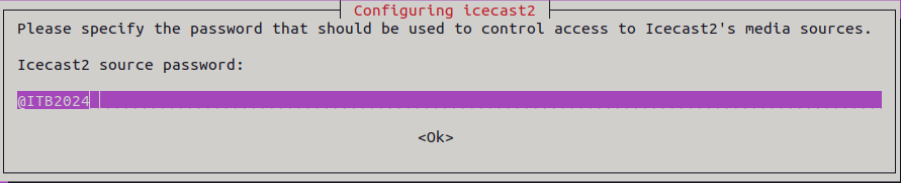
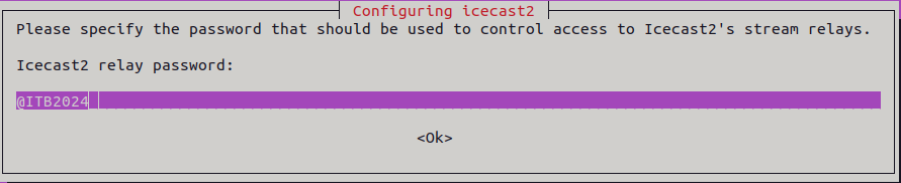
Para poder instalar este servicio se ejecuta el comando “apt install icecast2 -y”. Durante el proceso de instalación pide 3 tipos de contraseñas (sourcepassword, relaypassword y admin password).


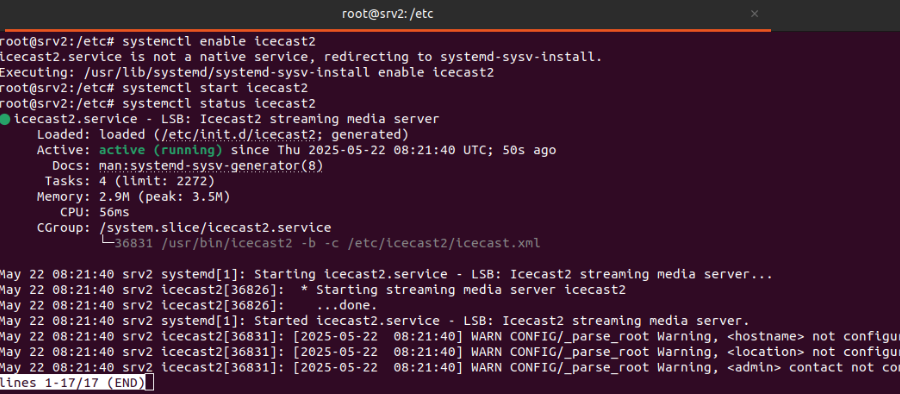
Seguidamente se instala DarkIce, que es una herramienta de captura y codificación de audio en tiempo real. Su función principal es tomar audio desde una fuente y enviarlo a un servidor de streaming como Icecast.
Para instalar darkice se ejecuta el comando “apt install darkice -y”.

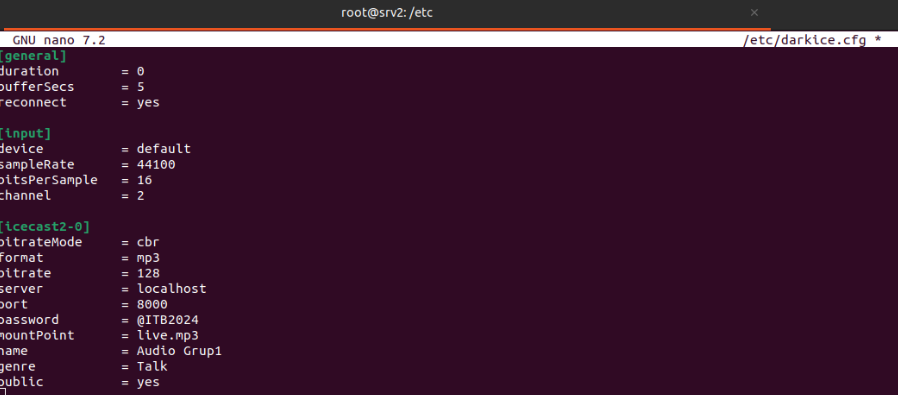
Se edita el fichero de configuración de darkice “/etc/darkice.cfg”.
Al estar usando una instancia de Amazon Web Service (AWS) no se dispone de tarjetas de sonido, por ende, se instala una imagen genérica de linux con el siguiente comando “apt install linux-generic-image”
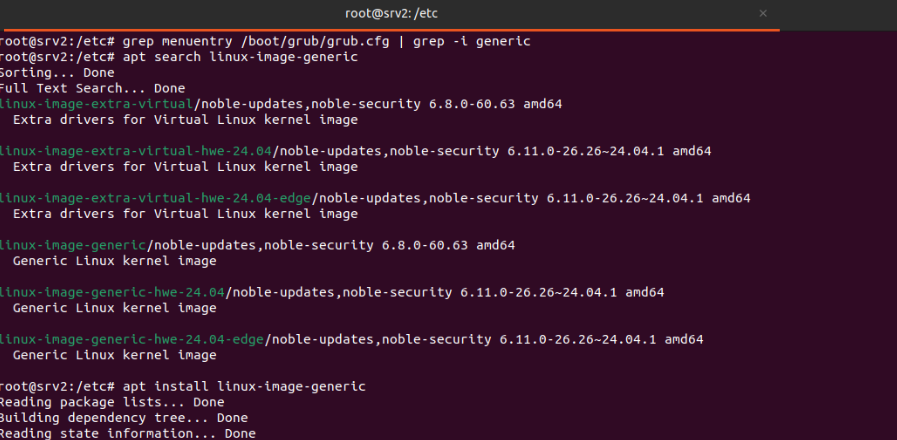
Se muestra la salida de la cual se dispone para poder copiar el menuentry seleccionado como se puede ver en la siguiente imagen. Esto servirá para configurar el grub por defecto.

Hay que acceder a “/etc/default/grub” y en la línea GRUB_DEFAULT= se añade el menuentry copiado anteriormente (Ubuntu, with Linux 6.8.0-60-generic).
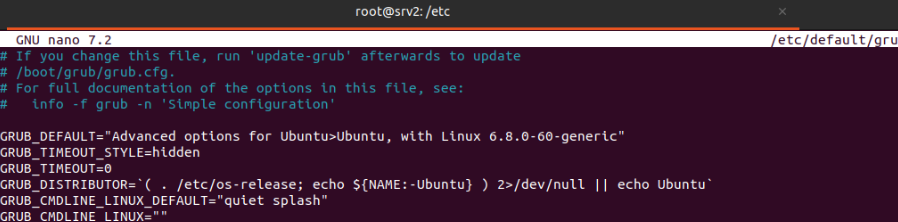
Se ejecuta el comando “sudo update-grub”, que actualiza la configuración del gestor de arranque GRUB, y luego “sudo reboot” para reiniciar y aplicar los cambios.
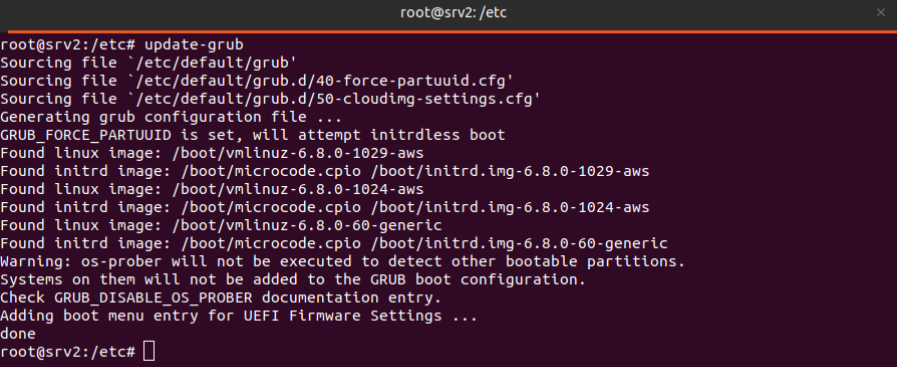
Se ejecuta el comando “aplay -l”, que muestra la lista de dispositivos de audio disponibles en el sistema. Sirve para identificar la tarjeta y el dispositivo de salida que usará en la configuración de audio.
| Se ejecuta _echo “snd-aloop | sudo tee -a /etc/modules_” para añadir el módulo snd-aloop _(dispositivo de loopback de audio) al archivo _/etc/modules, asegurando que se cargue automáticamente en cada arranque del sistema. |

Se abre “/etc/asound.conf” para editar el archivo de configuración global de ALSA, donde se define el comportamiento del sistema de sonido. Se utilizará un dispositivo loopback dado que no disponemos de tarjeta de sonido.
Se ejecuta “_apt install alsa-utils _” para instalar el paquete alsa-utils, que incluye herramientas esenciales para gestionar el sonido en Linux, como aplay, amixer y utilidades para configurar y probar dispositivos de audio.

Ejecutar “_systemctl restart alsa _” para reinicia el servicio de sonido ALSA y aplicar los cambios realizados en la configuración sin necesidad de reiniciar todo el sistema. Una vez hecha las anteriores configuraciones se reinicia el sistema.
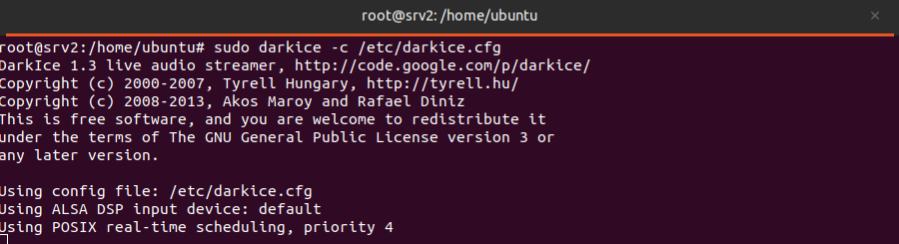
Se ejecuta “sudo darkice -c /etc/darkice.cfg” que inicia DarkIce usando el archivo de configuración especificado.
Para poder acceder a Icecast2, hay que acceder via URL, con nuestra IP pública y el puerto 8000.
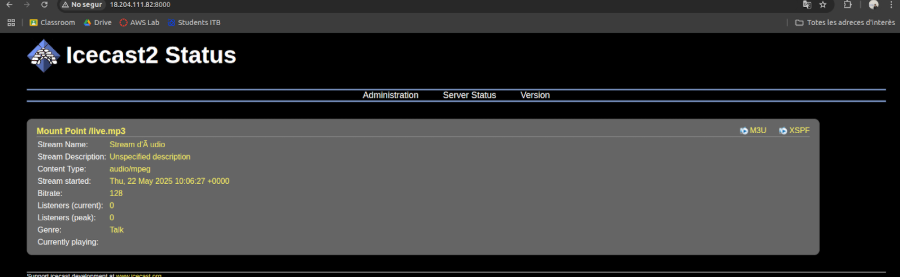
Streaming
Se debe actualizar la lista de paquetes disponibles desde los repositorios de Ubuntu. Seguidamente, se ha instalado el framework completo de GStreamer junto con sus plugins esenciales para procesamiento de vídeo y audio. Se añade herramientas de monitoreo de red (vnstat, iftop, iperf3) y utilidades para dispositivos de vídeo (v4l-utils).

Se habilita la capacidad de crear cámaras virtuales (/dev/videoX) que pueden ser alimentadas con contenido de archivos o streams para su retransmisión.
sudo apt install -y v4l2loopback-dkms v4l2loopback-utils

Se ha establecido el dispositivo /dev/video0 como cámara virtual operativa, lista para recibir contenido de vídeo y retransmitirlo como si fuera una cámara física, dado que AWS no dispone para las instancias.
Comandos utilizados:
sudo modprobe v4l2loopback devices=1 video_nr=0 card_label=”Virtual Camera” Carga el módulo del kernel v4l2loopback
echo ‘v4l2loopback’ | sudo tee -a /etc/modules Hace que el módulo se cargue automáticamente al iniciar el sistema
ls -la /dev/video* Lista todos los dispositivos de video disponibles
lsmod | grep v4l2loopback Verifica que el módulo esté cargado correctamente


Se abren los puertos UDP 5000 y 5004 en el firewall para permitir el tráfico de streaming RTP de entrada y salida. Se ha habilitado el puerto TCP 22 para garantizar el acceso SSH al servidor.
sudo ufw allow 5000/udp sudo ufw allow 5004/udp sudo ufw allow 22/tcp
Se crea un directorio donde se almacenan los videos con el comando “mkdir -p ~/videos”.

Se ha preparado el archivo test.mp4 como material de prueba para realizar las transmisiones de vídeo, quedando listo para usar en la ruta /home/ubuntu/videos/test.mp4.
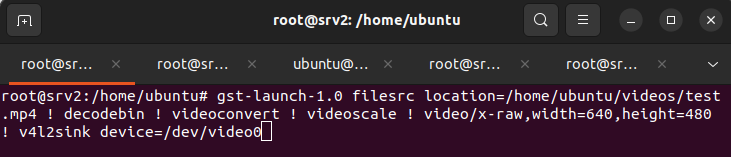
Retransmisión de Vídeo en Vivo con Protocolo RTP
Terminal 1 - Alimentación del Dispositivo Virtual Ejecutar la siguiente comanda que se encarga de alimentar el dispositivo de vídeo virtual con el contenido del archivo. Lee el test.mp4, lo decodifica, lo redimensiona a 640x480 píxeles y lo canaliza hacia /dev/video0 para que quede disponible como fuente de vídeo.
gst-launch-1.0 filesrc location=/home/ubuntu/videos/test.mp4 ! decodebin ! videoconvert ! videoscale ! video/x-raw,width=640,height=480 ! v4l2sink device=/dev/video0
Terminal 2 - Transmisión RTP
Ejecutar la siguiente comanda que transmitirá el vídeo por RTP al cliente. Captura el vídeo del dispositivo virtual, lo codifica en formato H.264 optimizado para baja latencia, lo empaqueta en formato RTP y lo envía vía UDP al cliente (srv3) en el puerto 5000.
gst-launch-1.0 v4l2src device=/dev/video0 ! videoconvert ! x264enc tune=zerolatency ! rtph264pay ! udpsink host=10.1.1.96 port=5000
CLIENTE (srv3 - 10.1.1.96)
En el cliente ejecutar la siguiente comanda que, recibe y reproduce el stream RTP. Escucha en el puerto 5000 los datos RTP entrantes, desempaqueta el vídeo H.264, lo decodifica y lo muestra en una ventana gráfica a través de X11 forwarding.
gst-launch-1.0 -v udpsrc port=5000 ! application/x-rtp,media=video,clock-rate=90000,encoding-name=H264,payload=96 ! rtph264depay ! h264parse ! queue max-size-buffers=10 ! avdec_h264 ! videoconvert ! autovideosink sync=false


Transmisión de Vídeo mediante ICECAST2
Se ha instalado FFmpeg como motor principal de codificación y transmisión.
sudo apt install ffmpeg
Seguidamente se ejecuta la transmisión directa del contenido hacia Icecast2. FFmpeg se encarga de procesar el archivo test.mp4 en tiempo real, aplicando codificación WebM con optimización de bitrate variable y enviando el stream resultante al servidor de distribución en el puerto 8000.
ffmpeg -re -i /home/ubuntu/videos/test.mp4 -c:v libvpx -b:v 500k -maxrate 600k -bufsize 600k -c:a libvorbis -b:a 64k -f webm -content_type video/webm -method PUT icecast://source:sourcepass@127.0.0.1:8000/stream.webm
Gestión de Conflictos del Sistema
Resolución de Incompatibilidades RTP-FFmpeg:
Al activar la retransmisión en vivo con RTP y FFmpeg simultáneamente pueden ocurrir errores de incompatibilidad, en ese caso ejecutar el siguiente comando:
sudo rmmod v4l2loopback
sudo modprobe v4l2loopback devices=1 video_nr=0 card_label=”Virtual Camera”
ls -la /dev/video0

Comprovación de ancho de banda con iperf3
Se instala iperf3 para hacer mediciones de ancho de banda entre servidores. Esta aplicación permite evaluar el rendimiento de la red y verificar la capacidad de transmisión.
Instal·lación: sudo apt install -y iperf3

Nota Importante sobre Reproducción de Vídeo Advertencia: Al ejecutar las siguientes comandas, hay que reproducir el vídeo.
Servidor (Receptor):
iperf3 -s
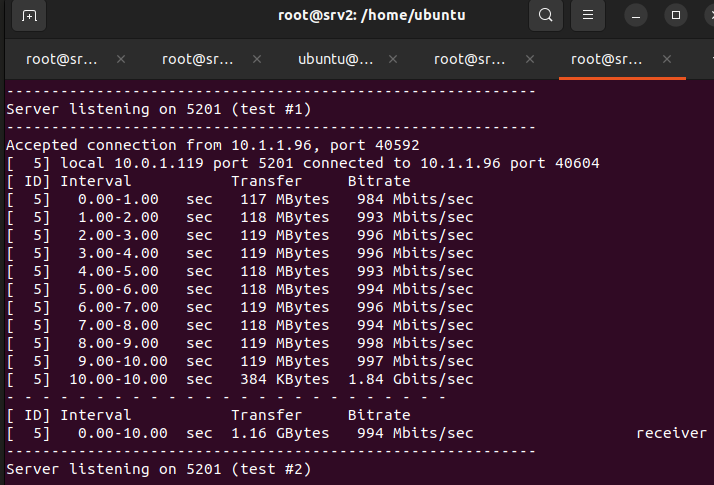
Cliente (Emisor):
iperf3 -c 10.0.1.119
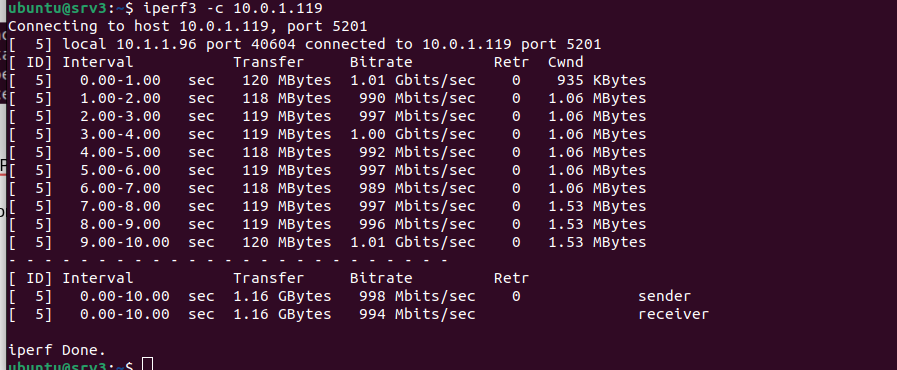
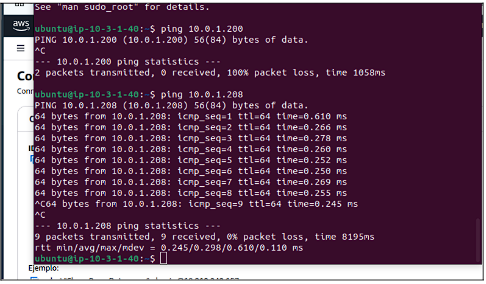
Se establece una configuración cliente-servidor donde el equipo receptor (srv1) actúa como destino de las pruebas de ancho de banda, mientras que el cliente (srv3) genera tráfico de prueba hacia la IP del servidor.
Configuración de Servidor 3
Para el servidor DNS y FTP se crea una instancia de tipo t2.micro con SO Ubuntu Server 24.04.
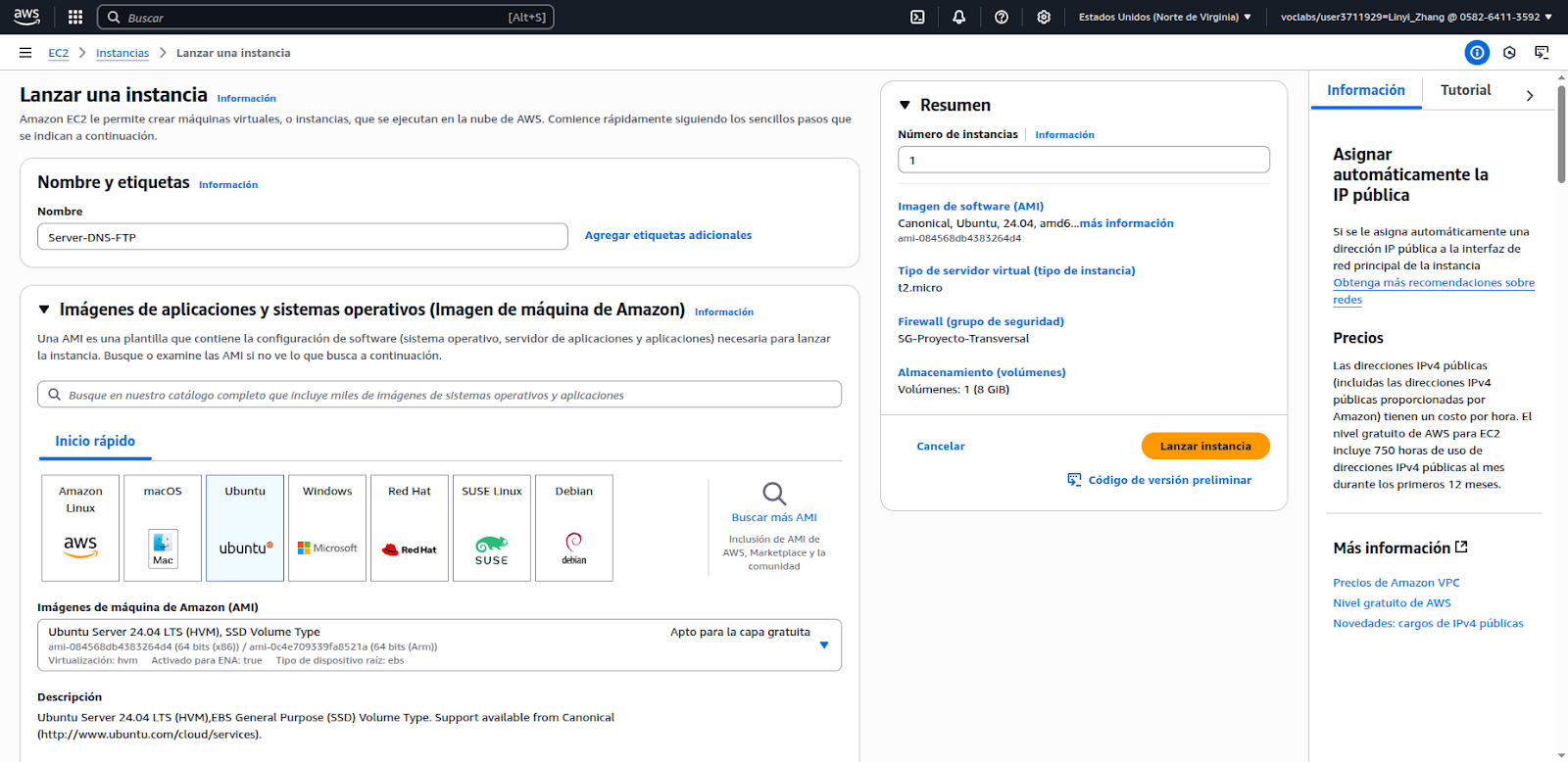
Se asigna una IP elástica, quiere decir que es una dirección IP pública estática que no cambia, incluso si la instancia se reinicia o se detiene.
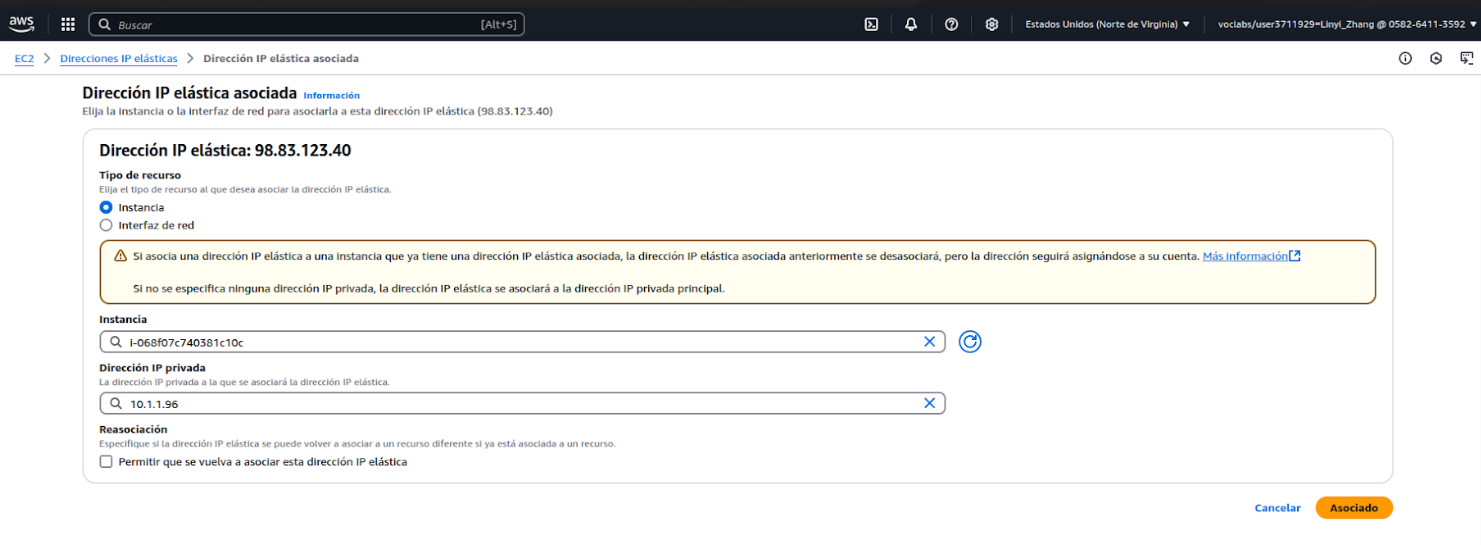 Se accede a la instancia mediante la clave privada por ssh. Cambiar los permisos a solo lectura para la clave privada.
ssh -i key_LZ.pem ubuntu@98.83.123.40
Se accede a la instancia mediante la clave privada por ssh. Cambiar los permisos a solo lectura para la clave privada.
ssh -i key_LZ.pem ubuntu@98.83.123.40

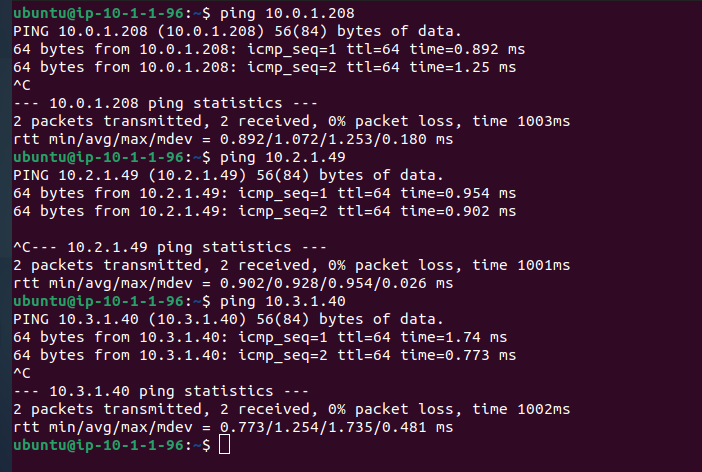
Se hace ping para comprobar que hay conectividad con los otros servidores.
DNS (Domain Name System)
El servicio DNS traduce nombres de dominio a direcciones IP y también la resolución inversa. Para ello hay que instalar el software principal que actuará como servidor DNS (bind9).
Para instalar bind9 hay que ejecutar la siguiente comanda: sudo apt install bind9
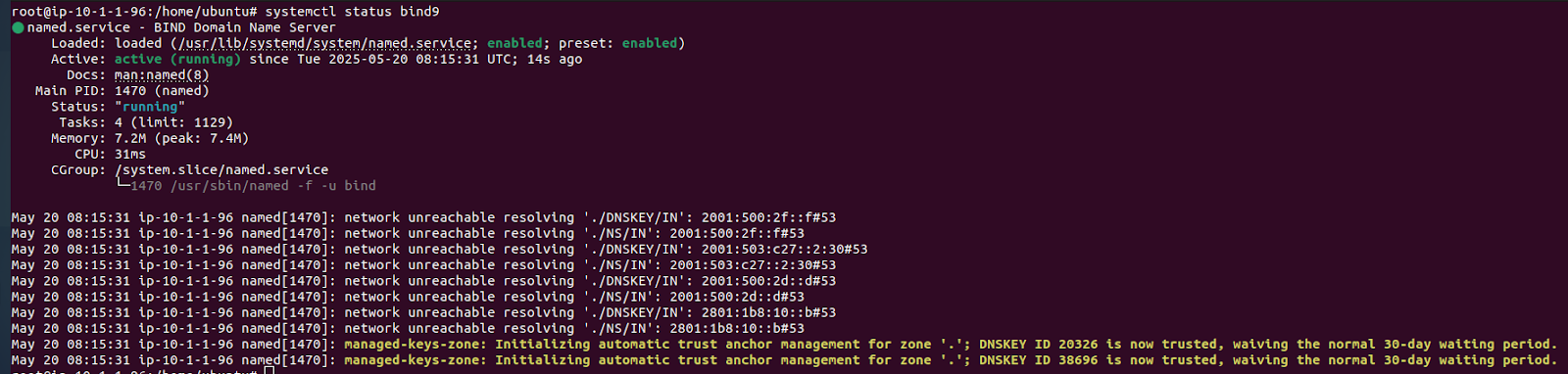
Cambiar el nombre del sistema modificando el archivo /etc/hostname para una mejor identificación del servidor dentro de la red.
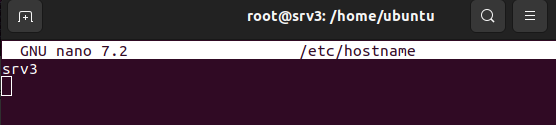
En el archivo /etc/hosts hay que asociar manualmente direcciones IP con nombres de dominio, permitiendo que el sistema resuelva esos nombres sin consultar un servidor DNS externo.
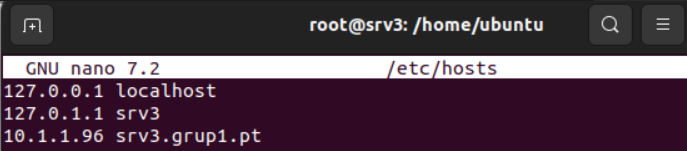
Se tiene que configurar la resolución DNS y el dominio de búsqueda modificando el archivo /etc/netplan/50-cloud-init.yaml
Añadir en el archivo /etc/systemd/resolved.conf la dirección IP del server y el dominio
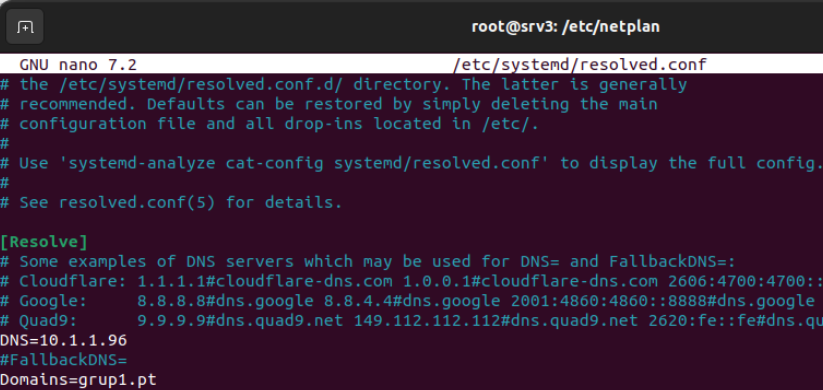
Hay que modificar el enlace del archivo /etc/resolv.conf. Ejecutar rm-f /etc/resolv.conf y volver a crear un enlace simbólico, ln -s /run/systemd/resolve/resolv.conf /etc/resolv.conf

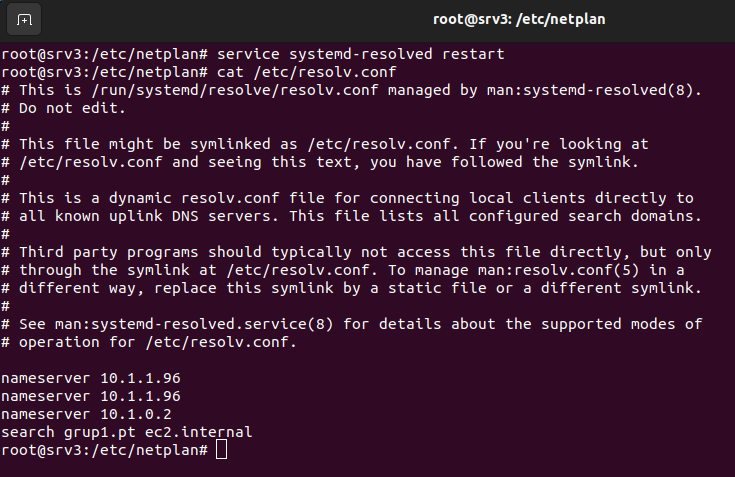
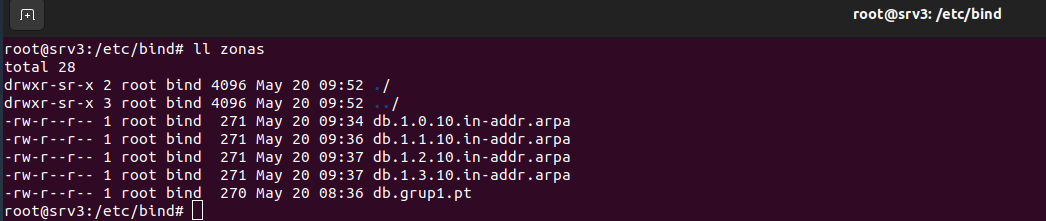
Hacer una copia de la plantilla de los archivos que contienen la configuración de la zona directa y la zona inversa. En nuestro caso, se decide guardar estas configuraciones en un directorio llamado zonas dentro de /etc/bind. (/etc/bind/zonas) La función de la zona directa es traducir nombres de dominio a direcciones IP y la inversa traducir direcciones IP a nombres de dominio.

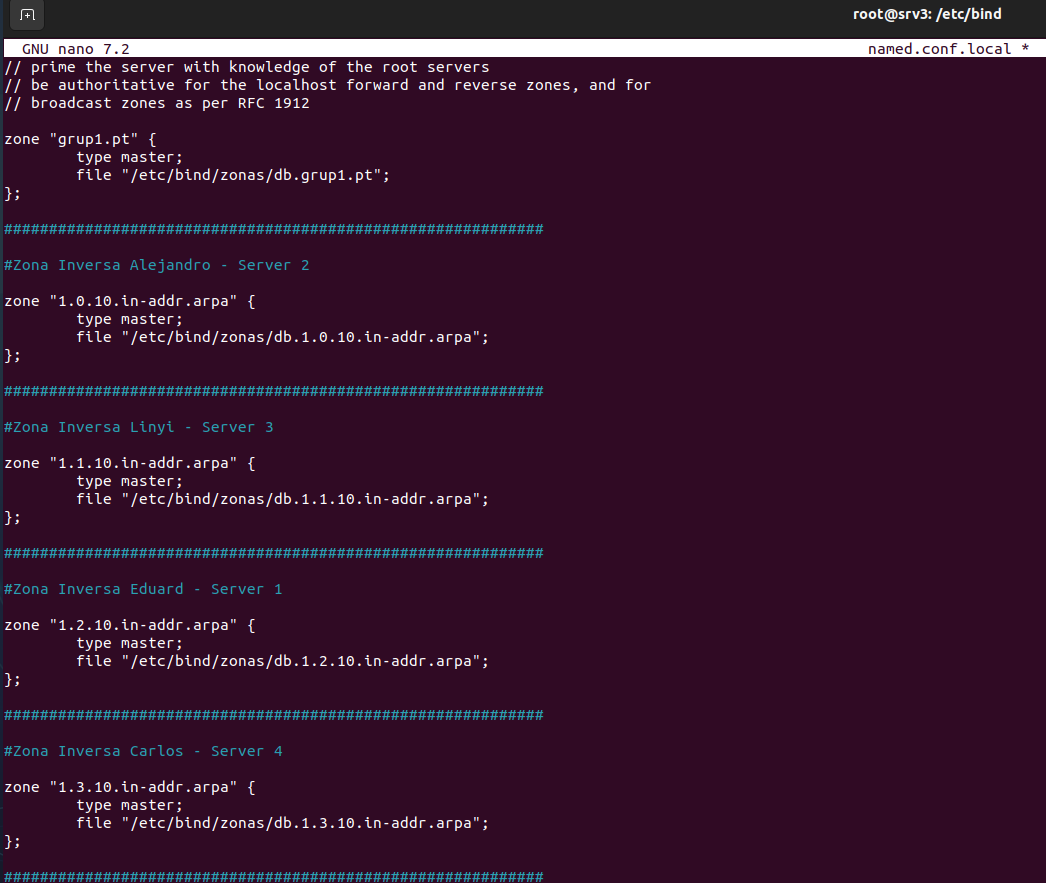
Configurar el archivo /etc/bind/named.conf.local para declarar las zonas directas e inversas asociadas con el dominio.
Modificar el archivo /etc/bind/named.conf.options El servidor DNS utilizará los servidores DNS externos con las direcciones IP 8.8.8.8 y 8.8.4.4 como reenviadores para resolver consultas de nombres de dominio que no estén en las zonas que el servidor gestiona directamente.
- Recursion yes; Habilita la resolución recursiva, permitiendo que el servidor DNS resuelva consultas para dominios que no gestiona directamente (por ejemplo, google.com) consultando otros servidores DNS en la jerarquía.
- Allow-recursion {10.0.0.0/8;}; Restringe la resolución recursiva a un rango específico de direcciones IP, en nuestro caso, la red 10.0.0.0/8. Solo los dispositivos en esta red pueden usar el servidor DNS para consultas recursivas.
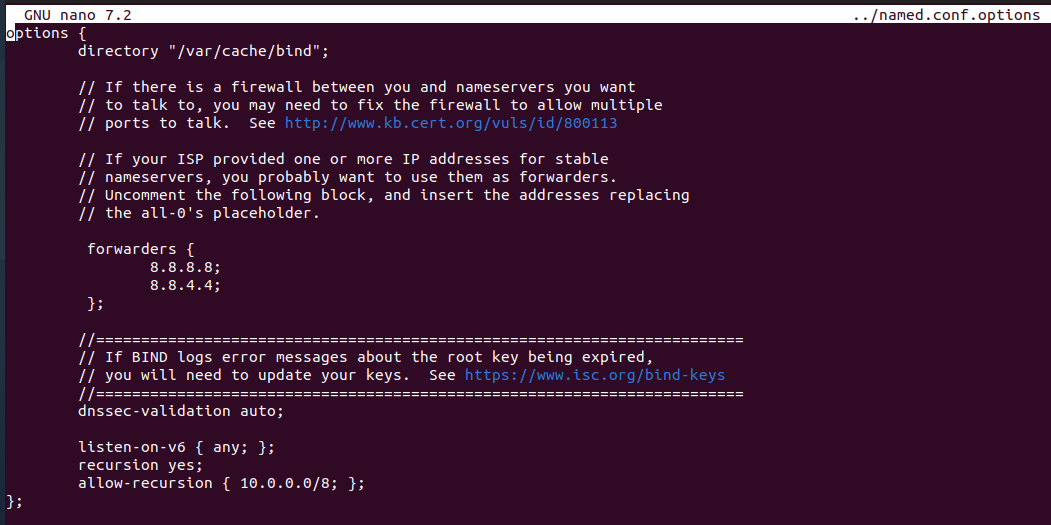
Modificar y añadir el parámetro -4 para que solo escuche peticiones del protocolo IPv4 en el archivo /etc/default/named, donde se configura parámetros de inicio del servicio Bind9.

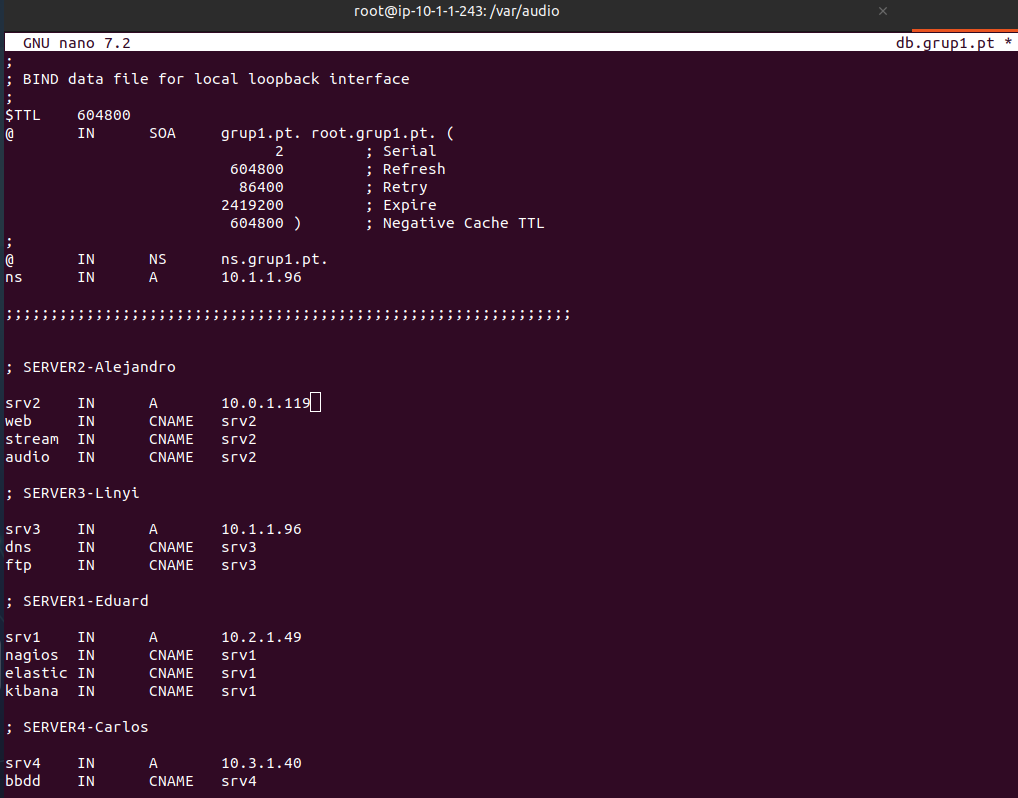
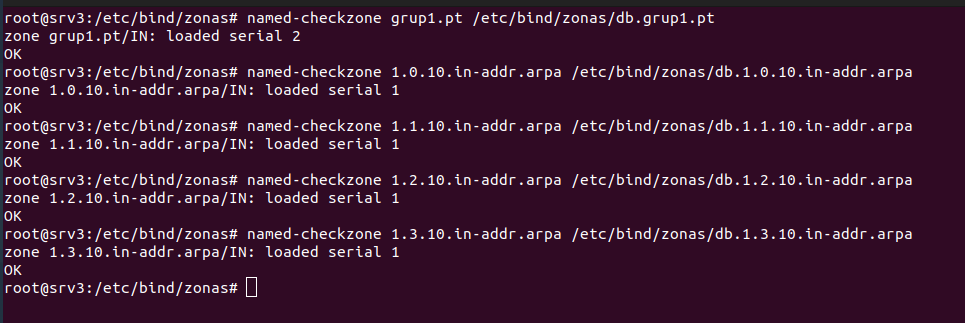
Modificar el archivo /etc/bind/zonas/db.grup1.pt para configurar la zona directa.
- @: Representa la zona grup1.pt.
- IN SOA: Indica que es un registro de tipo SOA, que define la autoridad de la zona.
- grup1.pt.: Nombre del servidor primario de nombres
- @ IN NS ns.grupi.pt.: Define ns.grup1.pt como el servidor de nombres autorizativo para la zona.
-
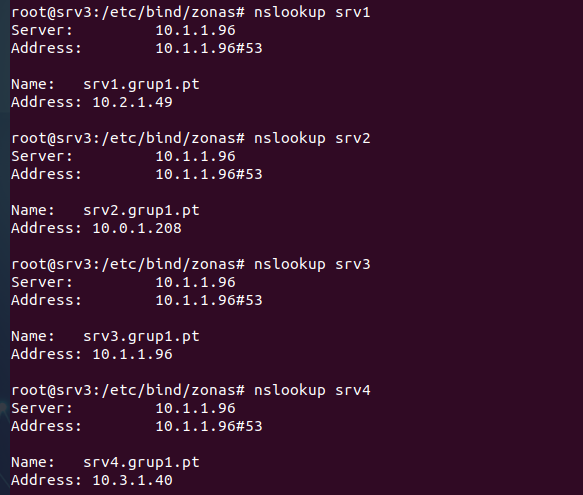
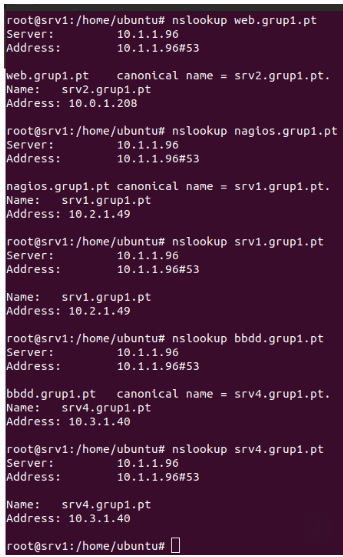
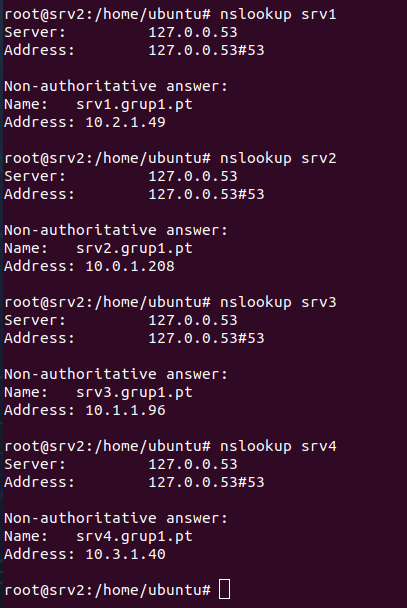
ns IN A 10.1.1.96: Asigna la dirección IP 10.1.1.96 a ns.grup1.pt, que corresponde a SRV3
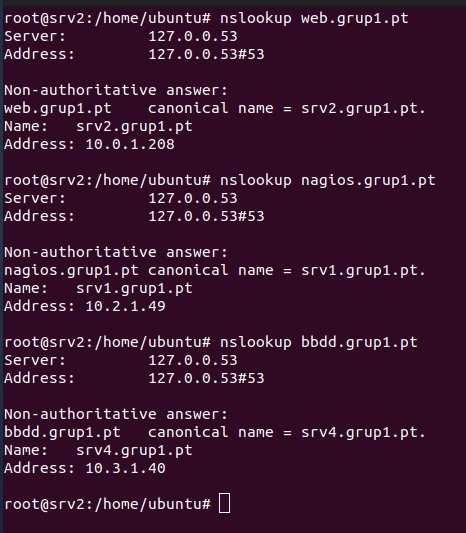
- IN A: asocia un nombre de host (como srv1.grup1.pt) a una dirección IP (como 10.2.1.49) para que los dispositivos puedan encontrar el servidor en la red.
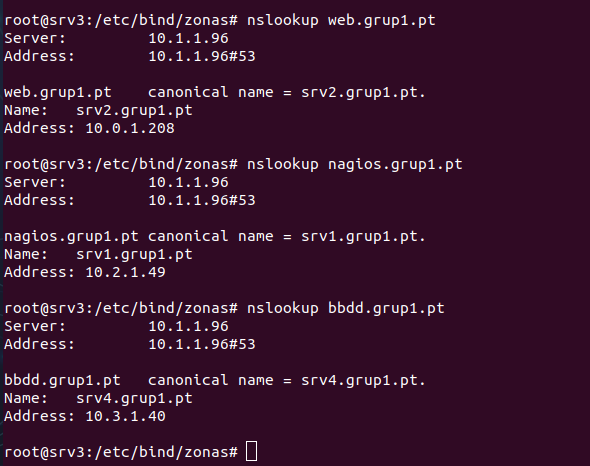
- IN CNAME: crea un alias (como nagios.grup1.pt) que apunta a otro nombre de host (como srv1.grup1.pt), para facilitar el acceso a servicios específicos sin duplicar IPs.
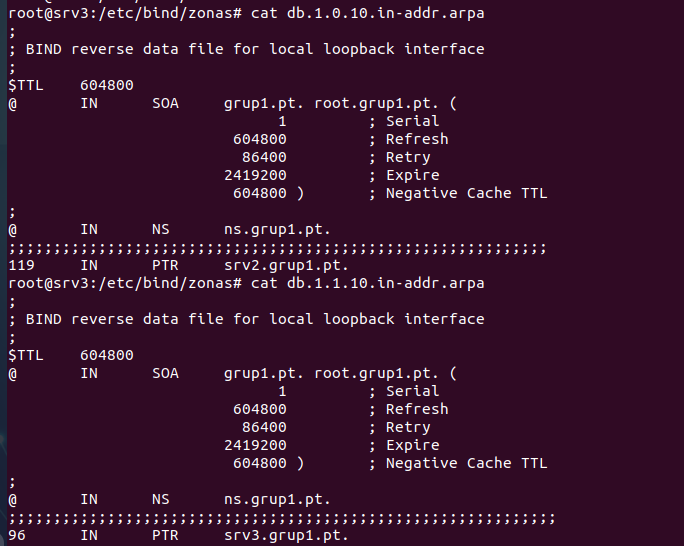
En el archivo de configuración para la zona inversa.
SOA y NS: Al igual que en la zona directa, definen la autoridad (SRV3 como servidor DNS). PTR: Asocia una IP a un nombre. La parte inversa, la IP sólo incluye los bytes relevantes dentro de la subred.
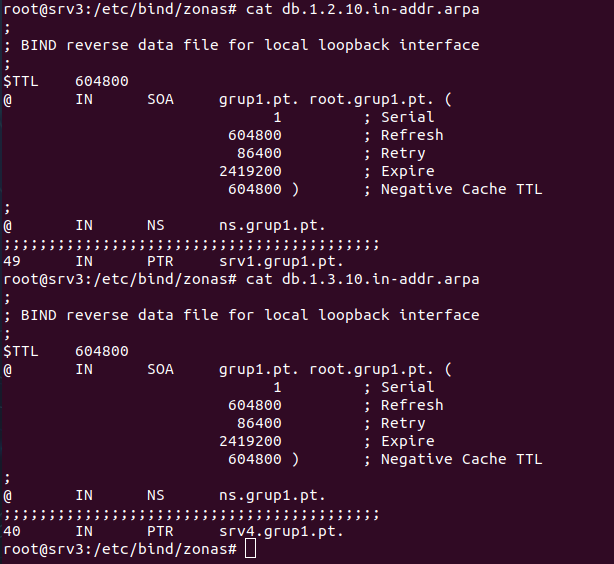
FTP
FTP es un protocolo de la capa de aplicación del modelo TCP/IP que facilita la transferencia de archivos entre un cliente y un servidor. Utiliza los puertos 21 (para comandos) y 20 (para datos) por defecto. Pero FTP no es un protocolo seguro, existen mecanismos para asegurar las conexiones entre clientes y servidores FTP como son; FTPS o enviar el protocolo FTP a través de un túnel SSH(SFTP).
SFTP es un protocolo que proporciona transferencia segura de archivos sobre una conexión SSH. A diferencia del FTP, SFTP encripta tanto las credenciales de autenticación como los datos transferidos, proporcionando mayor seguridad.
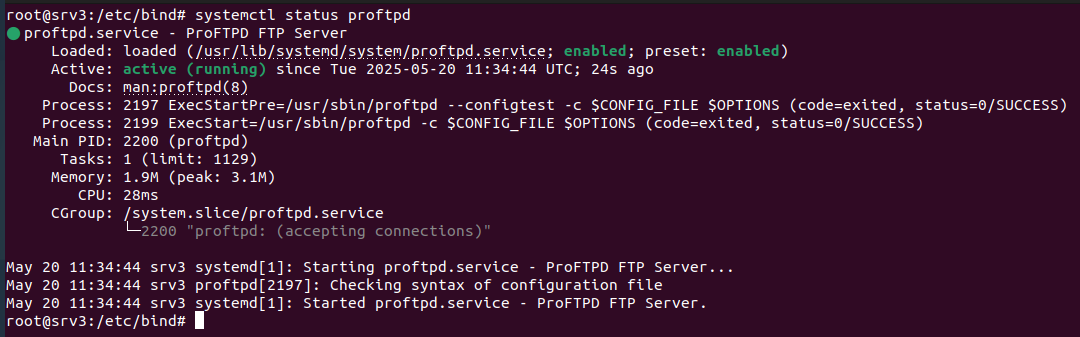
Para instalar el servicio proFTPD se ejecuta la siguiente comanda: sudo apt install proftpd
Se decide implementar SFTP como método principal de transferencia de archivos por la necesidad de garantizar la seguridad de los datos sensibles que se transmiten, especialmente teniendo en cuenta la presencia de información como la base de datos. Por este motivo se instala el servicio ssh que permite una transferencia segura.
Comando para instalar SSH: sudo apt install openssh-server
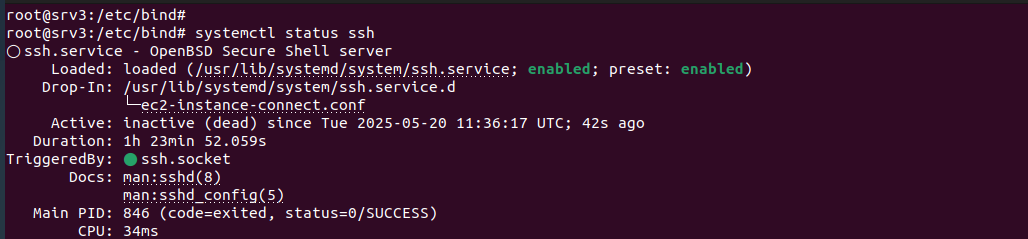
Editar el archivo principal /etc/ssh/ssh_config donde la guarda la configuración del servicio SSH.
Match Group sftpgroup: se aplica esta configuración sólo a los usuarios del grupo sftpgroup (se creará un grupo en el siguiente apartado)
ChrootDirectory %h: esta configuración sirve para restringir a los usuarios a su directorio personal (%h directorio home del usuario), evitando que puedan navegar fuera de ese directorio.
ForceCommand internal-sftp: fuerza de que los usuarios sólo puedan utilizar SFTP, no una shell completa (no pueden ejecutar bash).
AllowTcpForwarding no y X11Forwarding no: desactiva funcionalidades innecesarias para SFTP, reduciendo riesgos.
Para poder utilizar SFTP hay que activar el módulo LoadModule mod_sftp.c e instalar proftpd-mod-crypto.
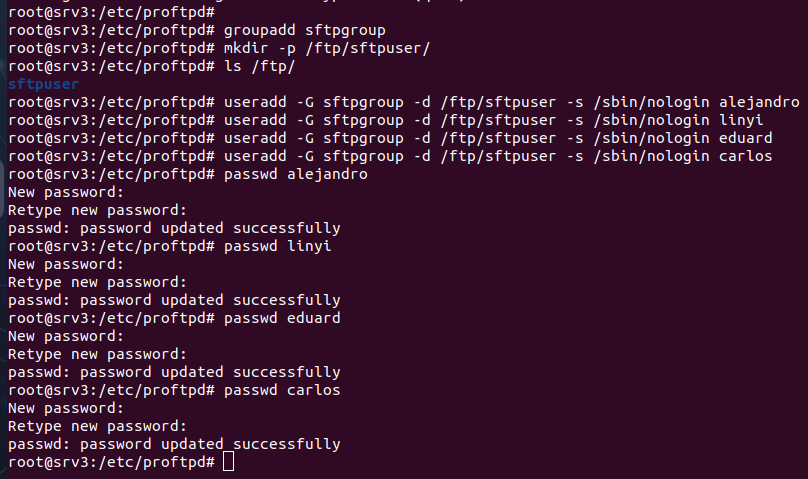
Se crea un directorio principal “mkdir -p /ftp/sftpuser” , esto sirve como base para alojar los directorios de los usuarios que utilizarán SFTP en el servidor, y un grupo “groupadd sftpgroup”, este grupo identifica a los usuarios autorizados a acceder a SFTP.
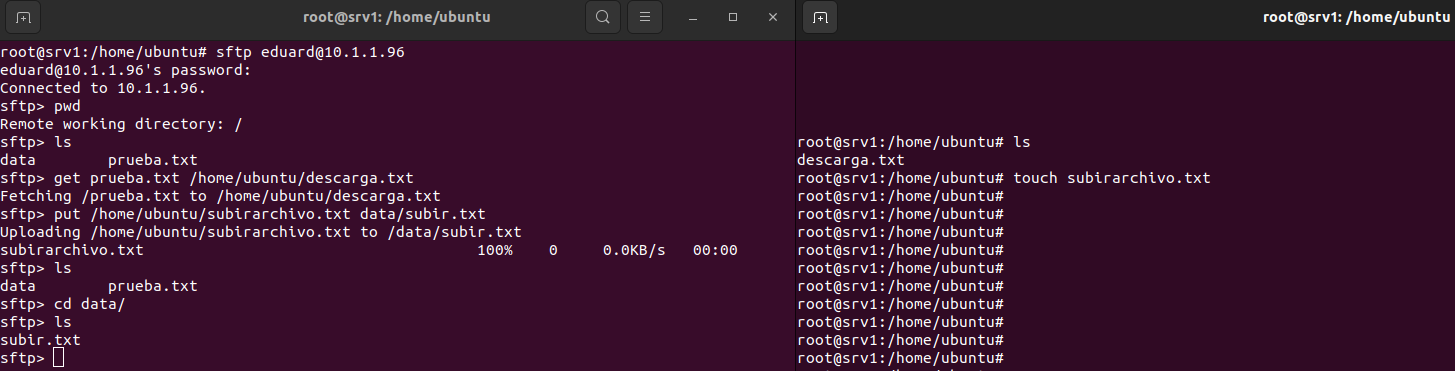
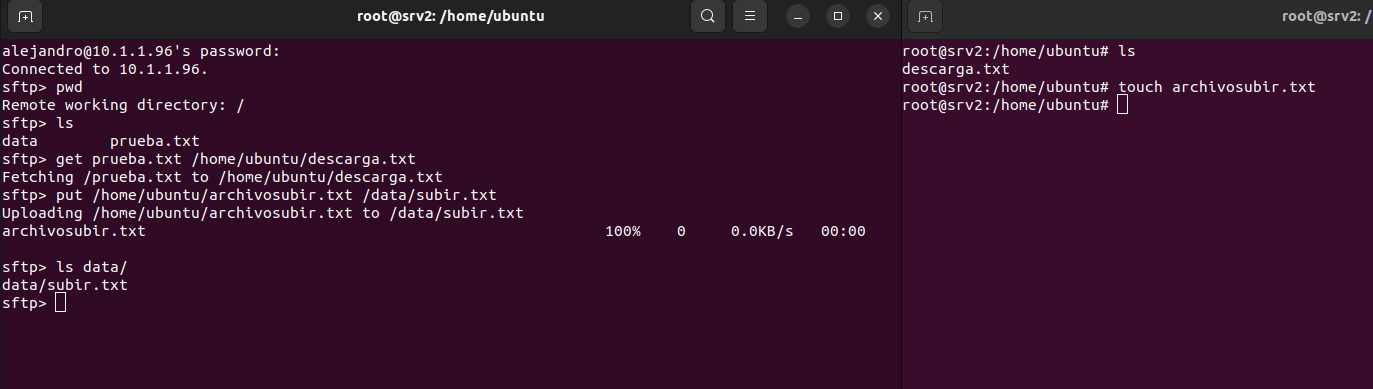
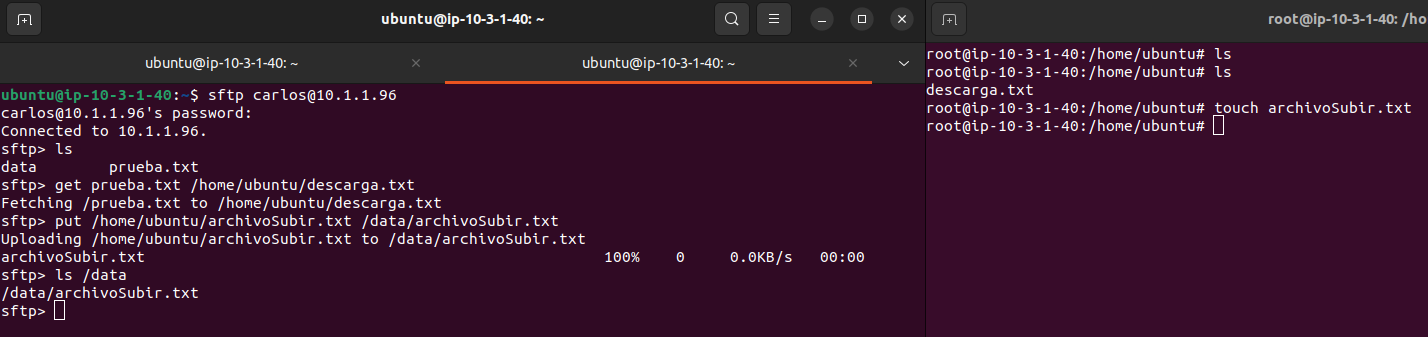
Los usuarios que se crean, son asignados al grupo y al directorio creado. Y además de establecer una contraseña para los usuarios con la comanda passwd. Se configura la shell en /sbin/nologin para limitarlos a SFTP, evitando que puedan acceder a una shell completa.
A continuación, el directorio /ftp/sftpuser es cambiado a root:root con comanda, “chown root:root /ftp/sftpuser”. Esto garantiza que sólo el administrador tenga control sobre la carpeta principal. Se añade permisos de lectura y ejecución al grupo sftpgroup con “chmod g+rx /ftp/sftpuser”. Esto permite a los usuarios del grupo acceder a sus directorios, pero no modificar la estructura principal.


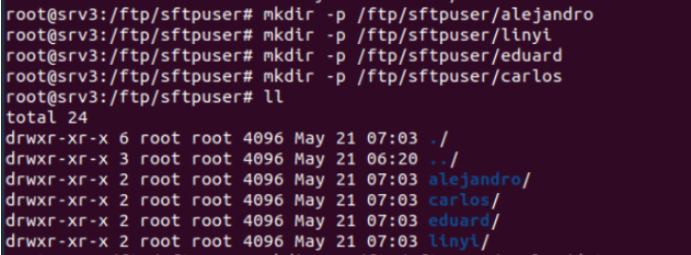
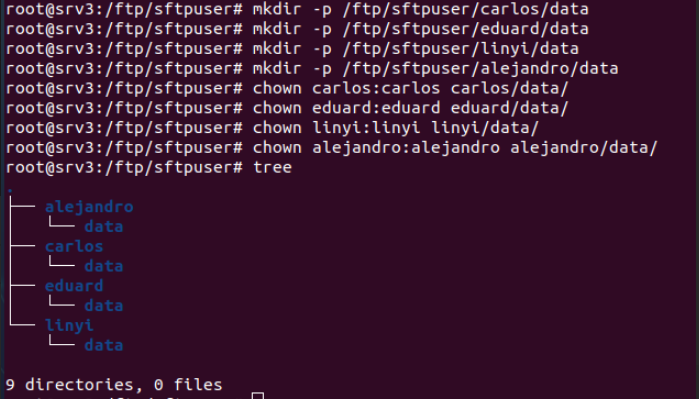
Se crean directorios individuales dentro de /ftp/sftpuser para cada usuario. Estos directorios sirven como espacio privado para cada usuario dentro del sistema SFTP. Además se crean subdirectorios llamados data dentro de cada directorio de usuario.
Cada usuario será el propietario de su directorio data. Cada usuario ha sido asignado como propietario de su propio directorio data, esto permite que puedan gestionar sus archivos.
Configuración de Servidor 4
Para nuestro caso de base de datos tenemos un Ubuntu Server 22.04 con conectividad al resto de máquinas y PostgreSQL instalado:
Previo a la creación de cualquier consulta, es necesaria la creación de un modelo entidad-relación, que será el siguiente:
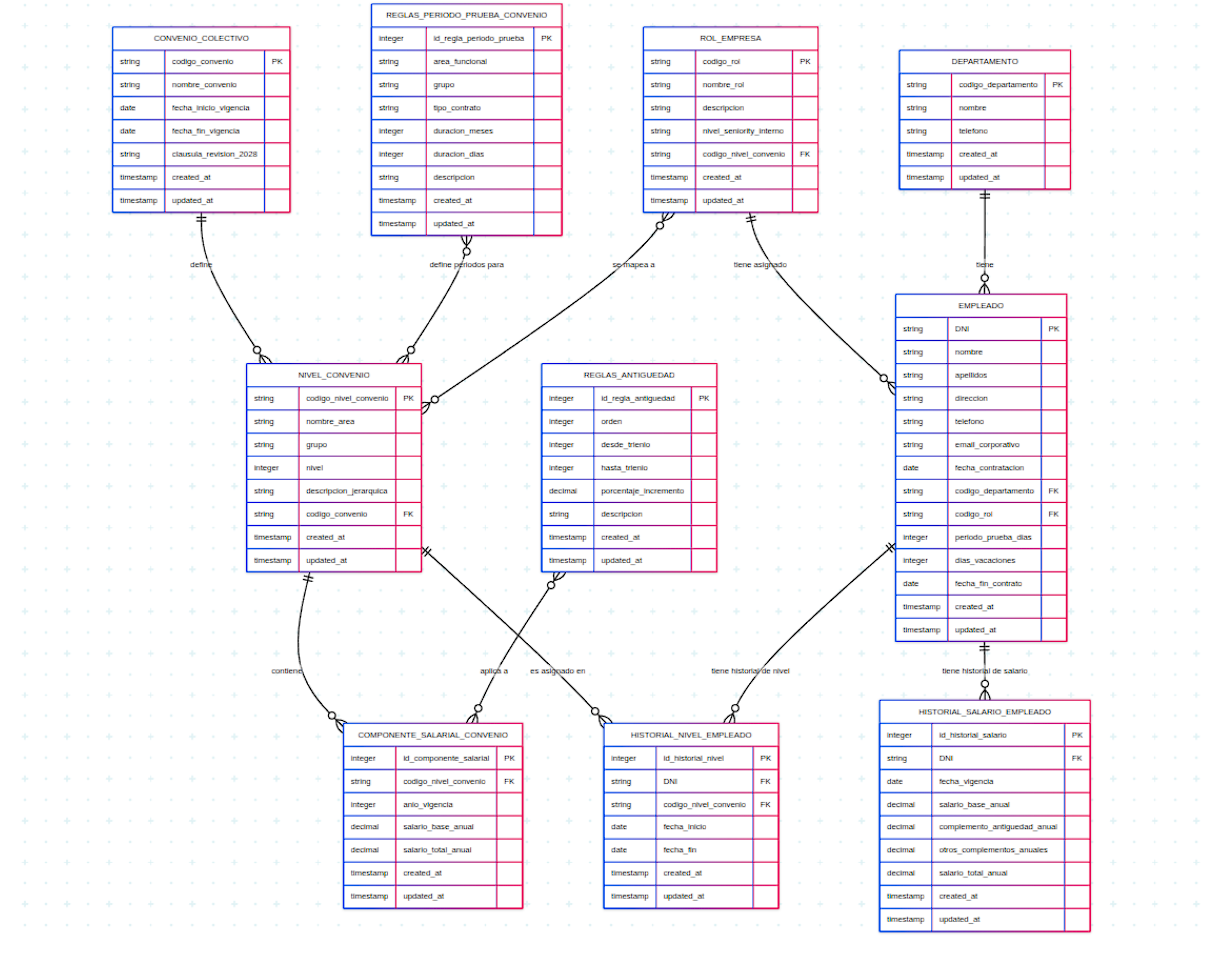
Con las siguientes relaciones:
Relaciones 1:N (Uno a Muchos):
CONVENIO_COLECTIVO - NIVEL_CONVENIO.
NIVEL_CONVENIO - COMPONENTE_SALARIAL_CONVENIO
NIVEL_CONVENIO - HISTORIAL_NIVEL_EMPLEADO.
DEPARTAMENTO - EMPLEADO.
ROL_EMPRESA - EMPLEADO.
EMPLEADO - (HISTORIAL_NIVEL_EMPLEADO).
EMPLEADO - (HISTORIAL_SALARIO_EMPLEADO).
Relaciones N:1 (Muchos a Uno):
ROL_EMPRESA-NIVEL_CONVENIO
Relaciones N:M (Muchos a Muchos):
REGLAS_ANTIGUEDAD - COMPONENTE_SALARIAL_CONVENIO.
REGLAS_PERIODO_PRUEBA_CONVENIO - NIVEL_CONVENIO.
Cada tabla tendrá una función importante en la base de datos y su precisión en los datos:
Funciones de cada tabla:
CONVENIO_COLECTIVO: Información básica de los convenios (Nombre, vigencia..)
NIVEL_CONVENIO: Almacena las diferentes áreas y grupos por los que separa el sector, el convenio colectivo.
COMPONENTE_SALARIAL_CONVENIO: Guarda los salarios base y totales mínimos anuales para cada nivel de convenio y año.
REGLAS_ANTIGUEDAD: Detalla los porcentajes de incremento salarial por trienios para calcular la antigüedad.
REGLAS_PERIODO_PRUEBA_CONVENIO: Define las duraciones estándar de los periodos de prueba por área y tipo de contrato.
ROL_EMPRESA: Contiene la definición de los roles internos de la empresa y su mapeo a niveles de convenio.
DEPARTAMENTO: Lista los departamentos de la empresa para organizar a los empleados.
EMPLEADO: Es la tabla central con la información personal y contractual básica de cada trabajador.
HISTORIAL_NIVEL_EMPLEADO: Registra los cambios de nivel de convenio de un empleado a lo largo del tiempo.
HISTORIAL_SALARIO_EMPLEADO: Guarda el historial de los componentes salariales de cada empleado en diferentes momentos.
Hecho el modelo, pasamos a los ajustes de seguridad:
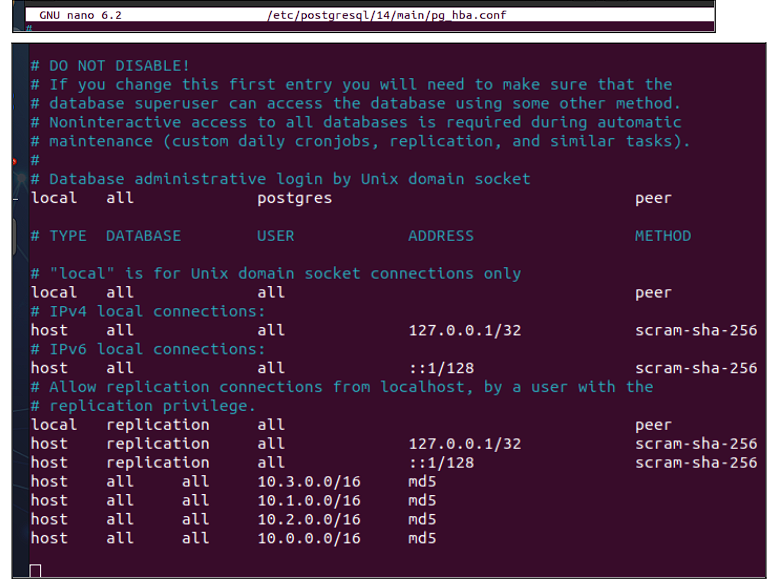
La base de datos aceptará entradas de todas las direcciones IP:
Y en este archivo se especifica quién puede conectarse. En este caso se decide añadir las redes de todas las máquinas presentes en este proyecto
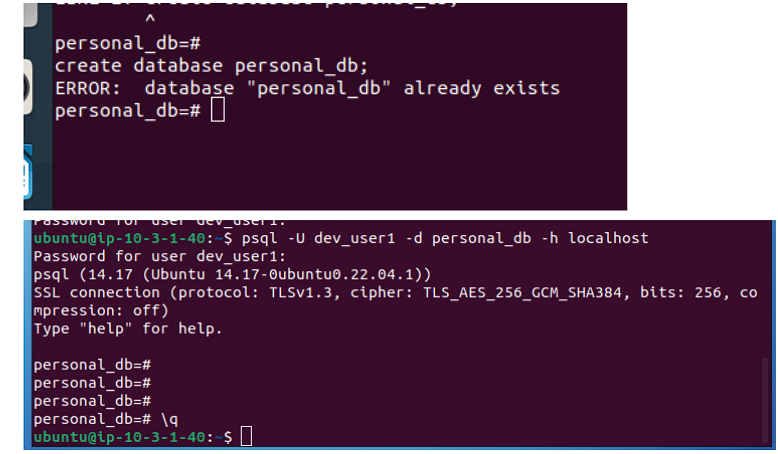
Se procede a la creación de la base de datos y de un usuario (Se adjunta prueba de la existencia de ambos objetos):
Y la creación de la base de datos:
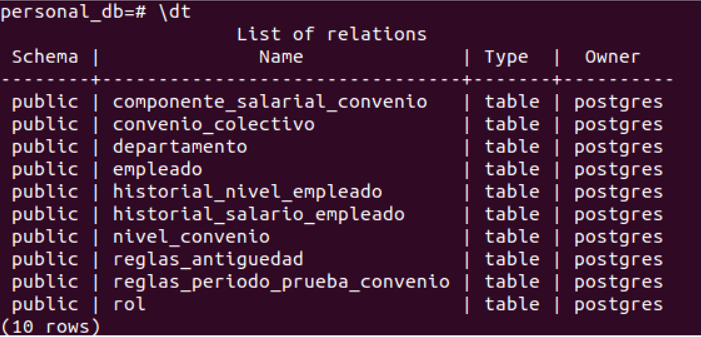
Base Datos
La base de datos ya está creada, y ahora es necesario darle una interfaz gráfica. Utilizaremos Flask, que permite crear webs rápidas a partir de Python y HTML:
 Se crea dos archivos:
-Un app.py que permita ejecutarse para iniciar el servicio:
Se crea dos archivos:
-Un app.py que permita ejecutarse para iniciar el servicio:
 -Unos HTML con los templates básicos:
-Unos HTML con los templates básicos:
 Y con esto ya tenemos una base de datos funcional:
Y con esto ya tenemos una base de datos funcional:
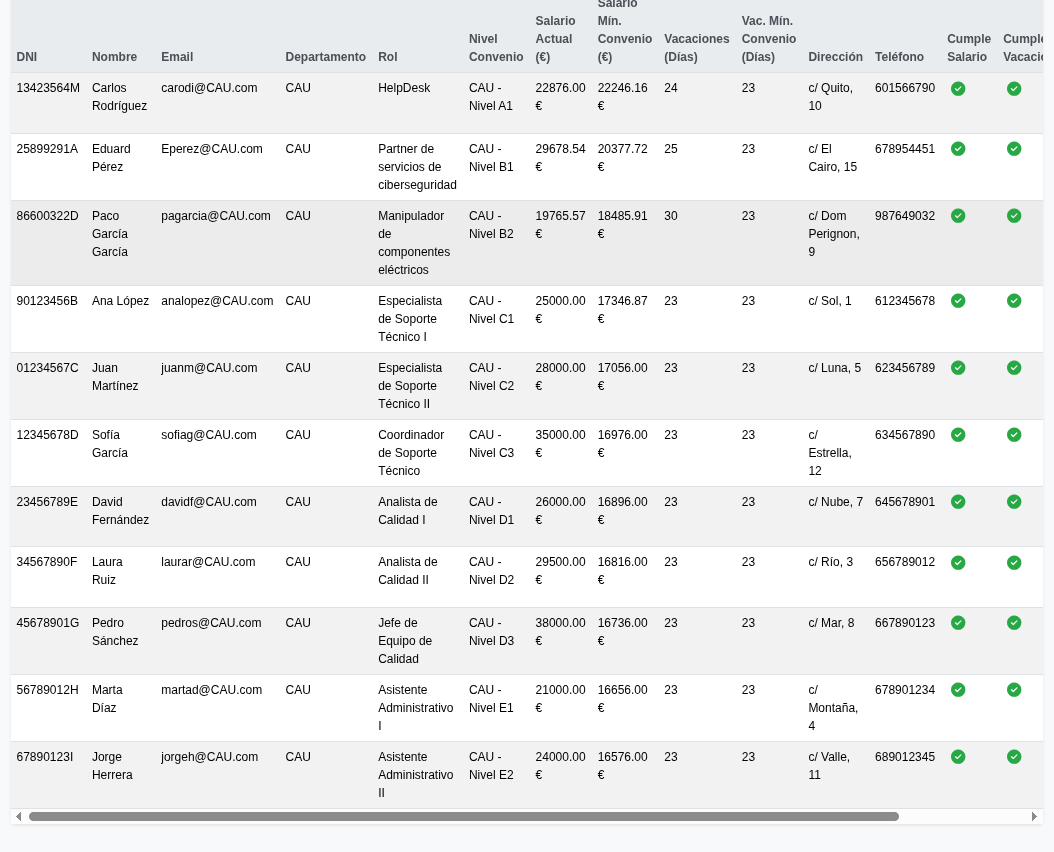 Luego podemos añadir los empleados que queramos:
Luego podemos añadir los empleados que queramos:
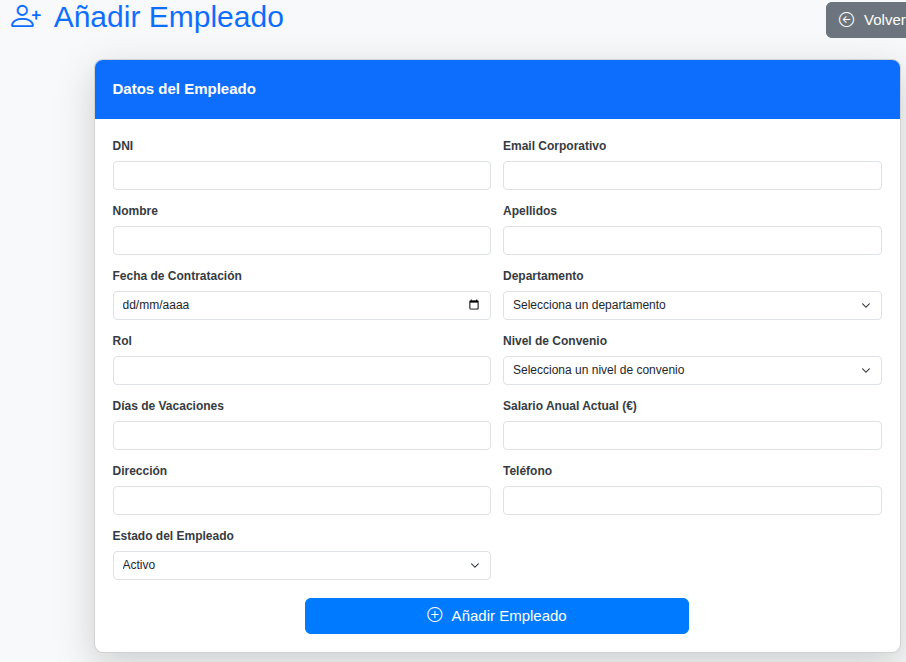 Y con esto la base de datos ya está operativa.
Y con esto la base de datos ya está operativa.
Configuración de Servidor 5
Copias seguridad
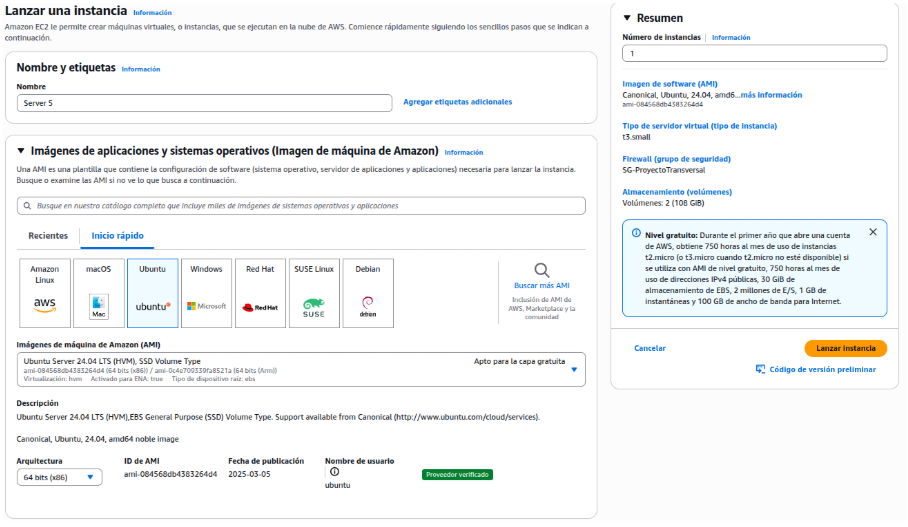
Se ha configurado una nueva instancia EC2 con el nombre “Server 5” para funcionar como servidor centralizado de backups. Se ha seleccionado la imagen Ubuntu Server 24.04 LTS. Además, se ha configurado el almacenamiento con 2 volúmenes totalizando 108 GB, divididos estratégicamente entre el sistema operativo y el espacio dedicado para backups.
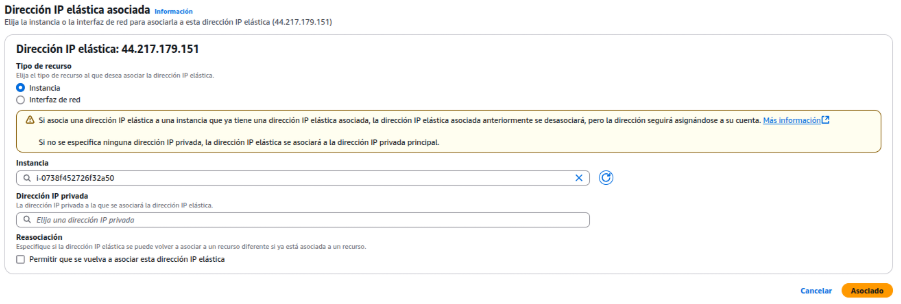
Se ha asociado una dirección IP elástica (44.217.179.151) al servidor de backup para garantizar conectividad externa consistente.
Se ha formateado el volumen de almacenamiento adicional (/dev/nvme1n1) utilizando el sistema de archivos ext4. Se ha creado el directorio principal /backups como punto de montaje para el volumen formateado, estableciendo la base donde se almacenarán todos los datos.
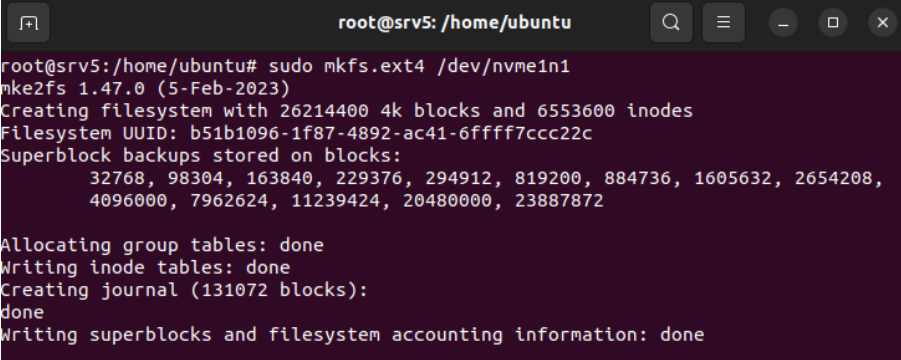

Se ha añadido una entrada al archivo /etc/fstab para configurar el montaje automático del volumen de backup, con esto, cada vez que se inicie el sistema se montará el volumen en su carpeta correspondiente.
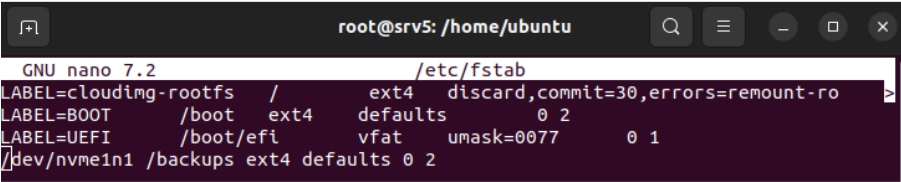
Se verifica el montaje correcto del volumen de backup mediante la consulta del espacio disponible en el sistema de archivos.

Se cambian los permisos y el propietario de la carpeta backups. Seguidamente, se crean las carpetas necesarias de forma organizada para tener una buena distribución de las copias de seguridad.

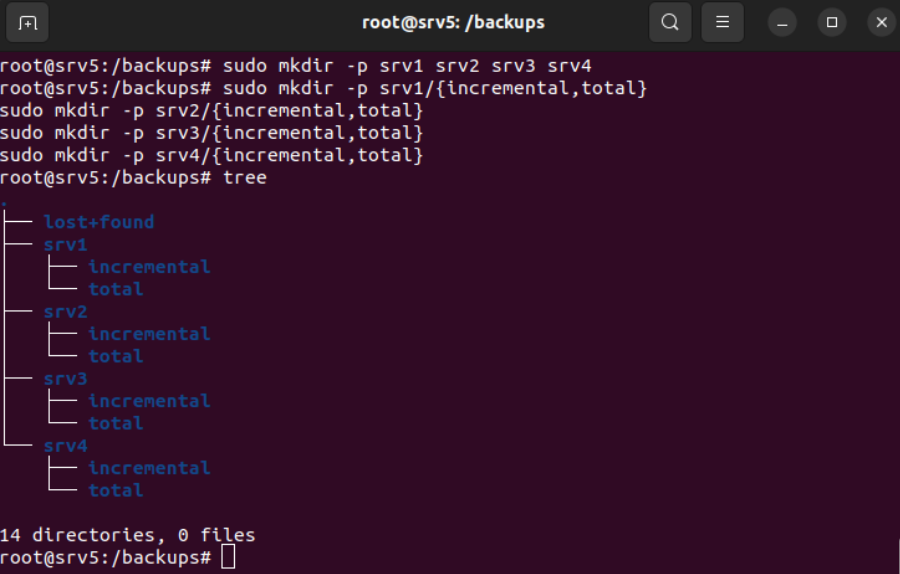
Se ha generado un par de claves SSH dentro del Servidor 5 y se almacenan en /home/ubuntu/.ssh/
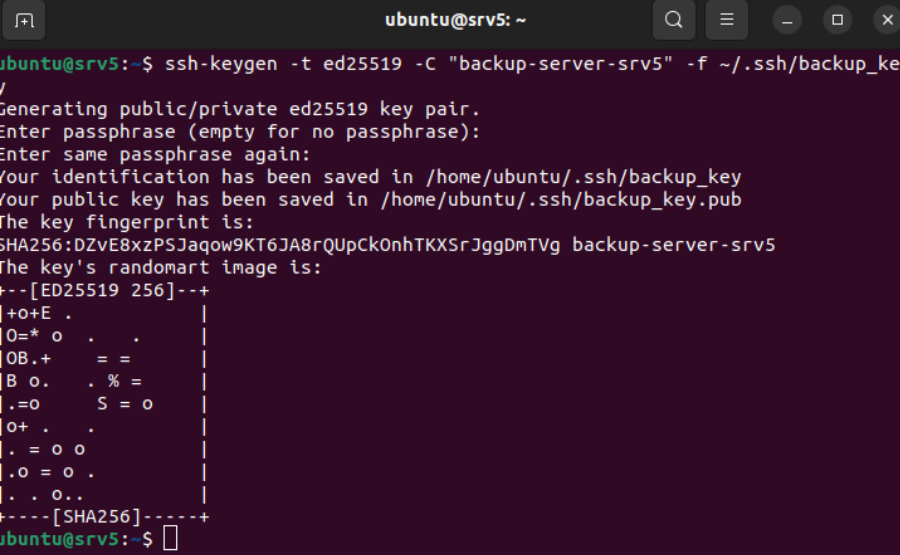
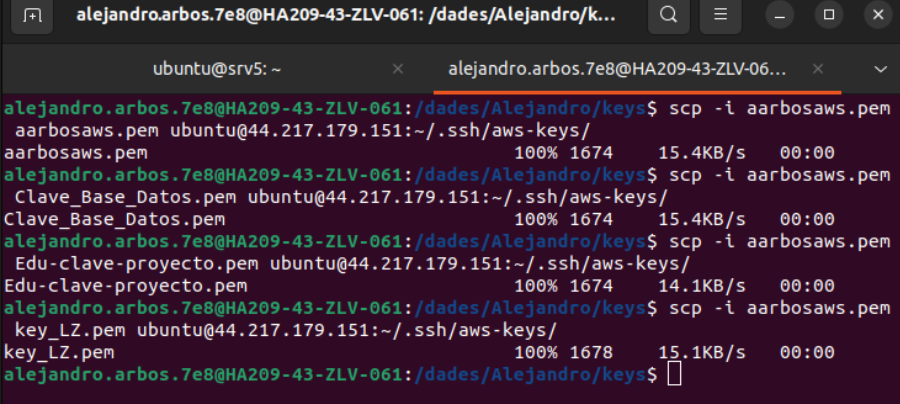
Desde la máquina local se envia todas las llaves de las otras instancias al Server 5 para poder acceder a estas, dado que para entrar via ssh debemos tener sus llaves correspondientes.

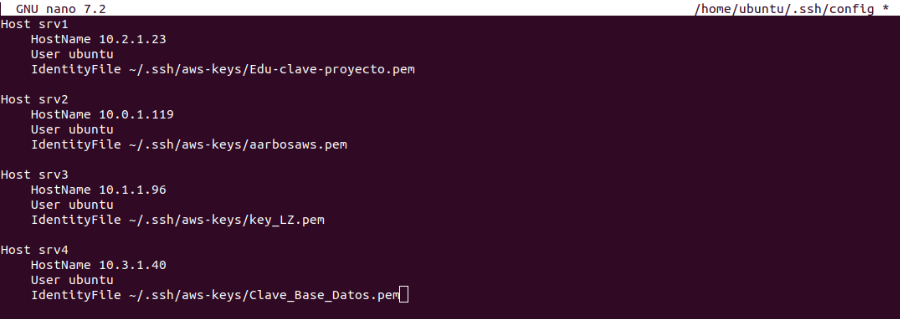
Se ha creado un archivo de configuración SSH que mapea cada servidor de la infraestructura con sus respectivas claves de autenticación privadas. Se han definido cuatro hosts (srv1, srv2, srv3, srv4) con sus direcciones IP privadas
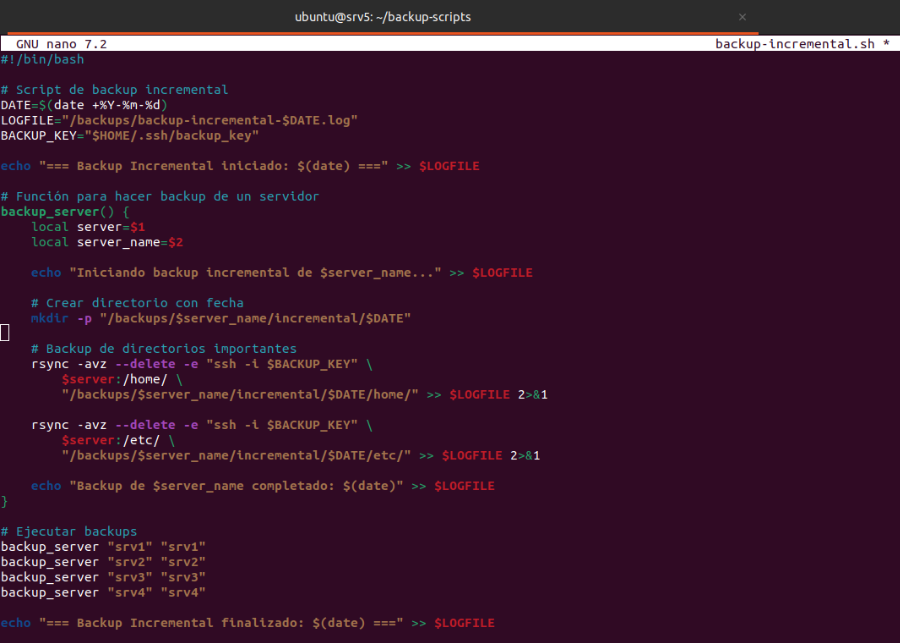
Crear una nueva carpeta la cual tendrá los dos scripts, tanto copias incrementales como total.

Se ha desarrollado un script automatizado de backup incremental que utiliza rsync para sincronizar datos de forma eficiente entre servidores.
Se asignan los permisos de ejecución al script de copias incrementales.

Se ha realizado una prueba del script y se han comprobado los archivos creados en sus rutas correctas.
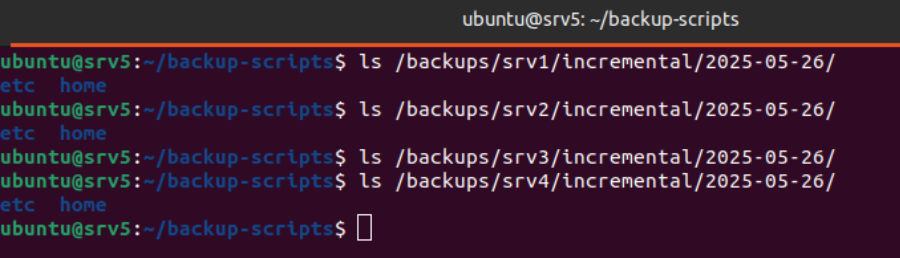
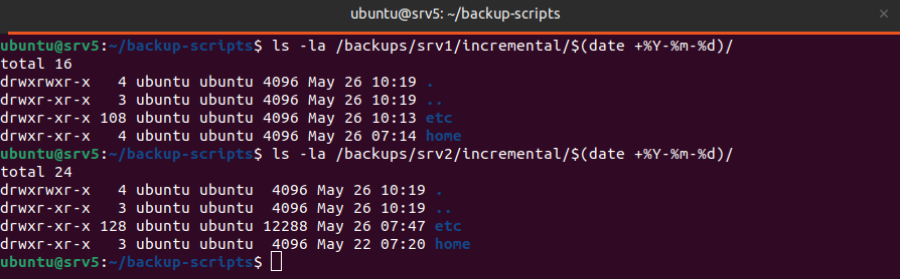
Se ha desarrollado un script de backup total semanal que extiende las capacidades del backup incremental para realizar copias completas del sistema.
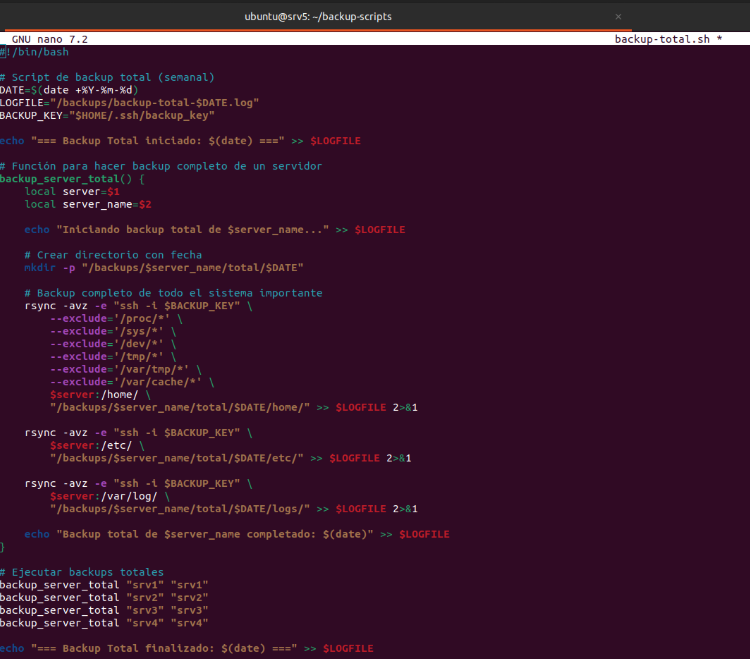
Se asignan los permisos de ejecución al script de copias total.

Se comprueba la estructura de directorios de backup verificando la existencia de los directorios /backups/srvX/total/ para cada uno de los cuatro servidores. La verificación confirma que se han creado correctamente los subdirectorios
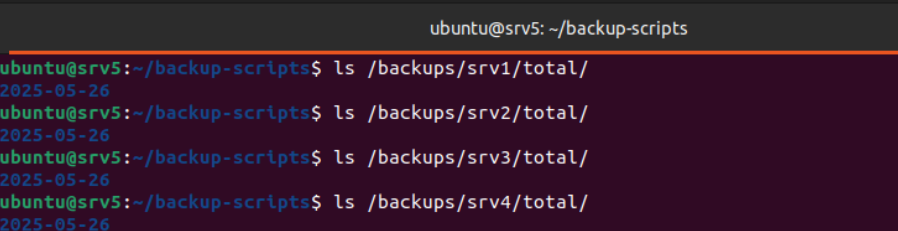
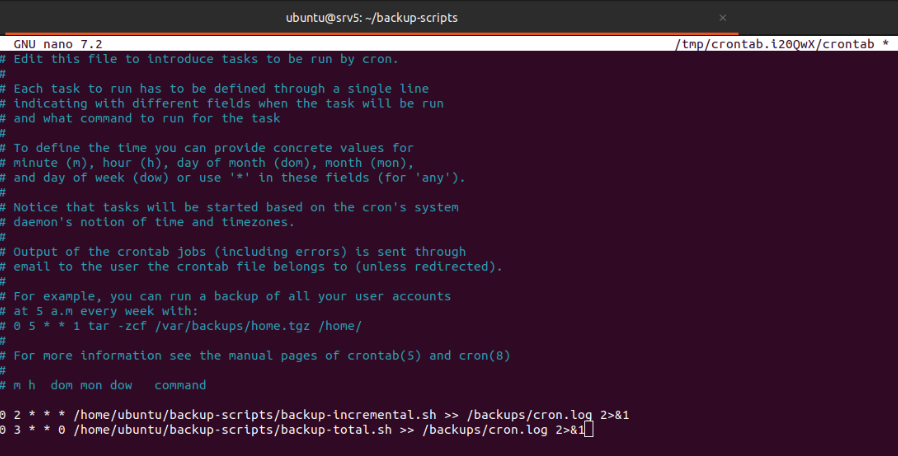
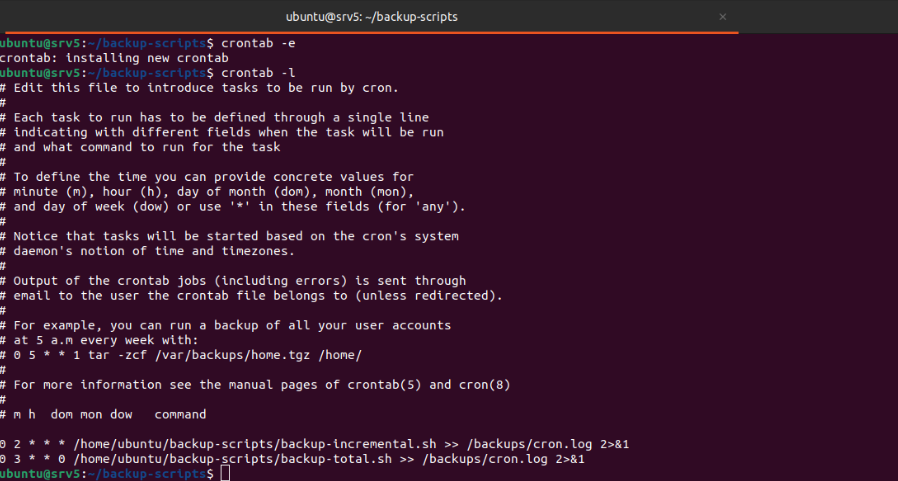
Como último paso, modificar el archivo de crontab para que ejecute los scripts de forma automática.